3.1. 代表的なアーキテクチャ#
3.1.1. AlexNet#
2012 年以前、画像分類といえば、画像から特徴量を抽出し、その特徴をもとに分類を行うのが一般的でした。このとき、物体の色や形状、輝度といった特徴量は人が設計しており、いかに優れた特徴を設計できるかが分類性能を左右していました。しかし、2012 年に Hinton 教授のチームが発表した AlexNet 5 は、この手作業による特徴量設計を不要にする画期的なモデルとして注目されました。AlexNet は、大量のデータさえあれば、機械自身が有用な特徴量を学習できることを証明し、深層学習の可能性を大きく広げました。
AlexNet は、3 つの畳み込み層、2 つのプーリング層、そして 3 つの全結合層で構成されています(Fig. 3.1)。入力は 224×224 ピクセルの正方形画像で、出力は 1,000 次元のベクトルです。このベクトルの要素が、入力画像が ImageNet 1 の 1,000 クラスに属する確率を表しています。
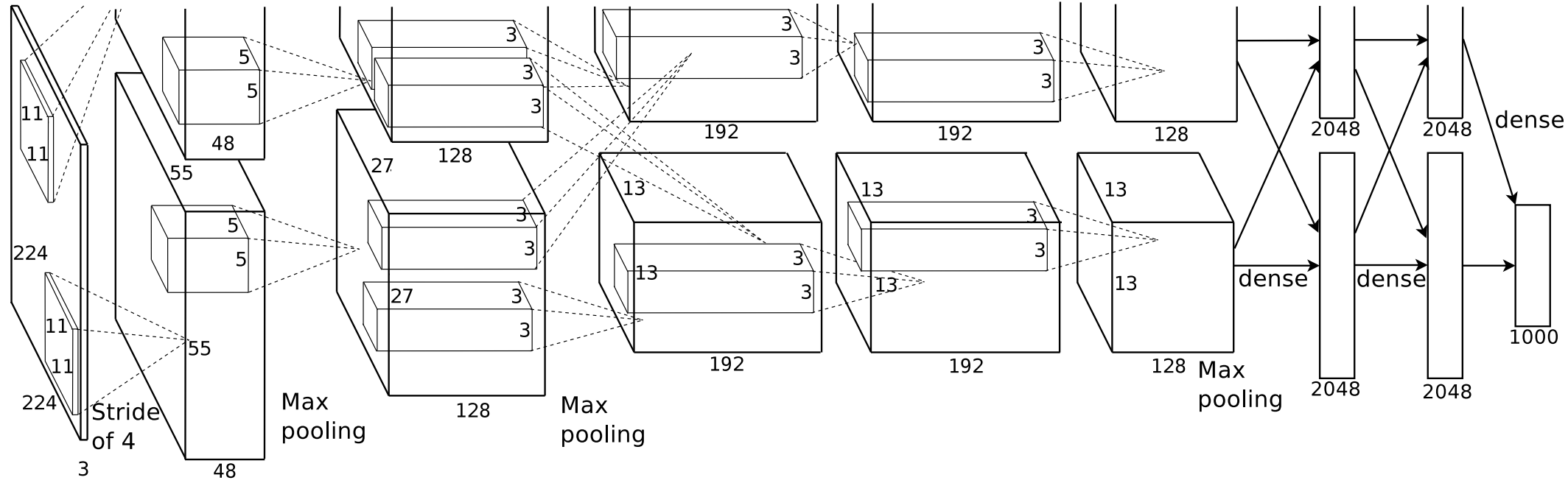
AlexNet では、モデルを訓練するときに、効率化のために 1 枚の画像を上下に分割し、それぞれを異なる GPU で並列処理した後、最終的に全結合層で統合するという方法が採用されました。この工夫により、大規模なモデルの訓練を可能にしました。また、AlexNet は、GPU を活用した高速な訓練のほかにも、いくつかの革新的な技術を取り入れました。例えば、活性化関数として従来のシグモイド関数や tanh 関数に代わり、ReLU(Rectified Linear Unit)関数を採用しました。ReLU 関数は非常にシンプルであり、計算量が少ないのが特徴です。そのため、モデルの訓練時間の大幅に短縮することができました。また、データ不足を補うために、画像を反転させたり回転させたりするデータ拡張(augmentation)を導入し、モデルの汎化性能を向上させました。さらに、学習時に一部のニューロンをランダムに無効化する Dropout を取り入れることで、過学習を防ぎつつ、モデルの汎化性能を改善することができました。
2012 年、AlexNet は ILSVRC(ImageNet Large Scale Visual Recognition Challenge)8 で優勝し、それまでの技術を大きく凌駕する成果を上げました。この成功を受けて、深層学習が一躍注目を集めるようになりました。その後、Inception や ResNet といった新しいアーキテクチャが登場し、AlexNet は主流から外れていきましたが、ReLU やデータ拡張、Dropout といった技術は、深層学習モデルの設計における標準技術として広く活用されています。
3.1.2. ZFNet#
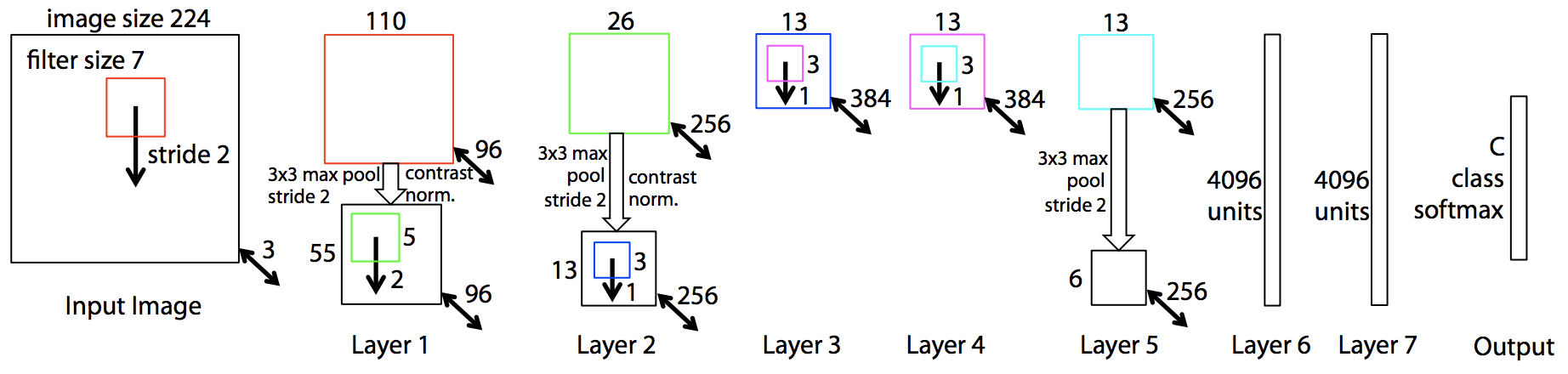
ZFNet 14 は、AlexNet の問題点を改良したアーキテクチャで、2013 年の ILSVRC コンテスト 8 で 1 位を獲得しました。AlexNet では、第 1 層の畳み込み層に 11×11 のカーネルを使用していましたが、この大きなカーネルサイズが画像の詳細な特徴を十分に捉えられない原因となっていました。ZFNet では、この問題に対処するため、第 1 層のカーネルサイズを 7×7 に縮小し、画像の細部情報をより効果的に抽出できるようにしました。
さらに、AlexNet では第 1 層目でのカーネルのスライディング距離(ストライド)が 4 ピクセルに設定されていました。このストライド幅が大きいと、エイリアシングが発生しやすくなります。例えば、斜線を含むオブジェクトが畳み込み処理後に階段状の線に変わるといった問題が見られました。ZFNet はこの点を改良し、ストライドを 2 ピクセルに変更することでエイリアシングを軽減しました。これらの改良により、ZFNet は AlexNet の問題点を対策しつつ、ほぼ同様の構造を維持しています(Fig. 3.2)。
3.1.3. VGGNet#
VGGNet (3) は、2014 年のISLVRC コンテストで第 2 位を獲得したアーキテクチャです。この研究は、ネットワークの層数が分類性能に与える影響を体系的に調査したもので、深層学習における重要な成果として知られています。
VGGNet の研究チームは、層数の異なる 6 種類のアーキテクチャを設計し、画像分類性能の比較を行いました(Fig. 3.3)。最初に基本となる 11 層のモデルを構築(VGG11)し、次に AlexNet で用いられていた局所応答正規化(Local Response Normalization, LRN)の効果を調べるため、VGG11 の第 2 層に LRN を追加したモデル(VGG11-LRN)を作成しました。LRN は、特徴マップのチャンネル間で値を正規化することで、学習の安定性やモデルの汎化性能を向上させるとされていましたが、VGG11 と VGG11-LRN の比較では、LRN の追加による性能向上は見られませんでした。
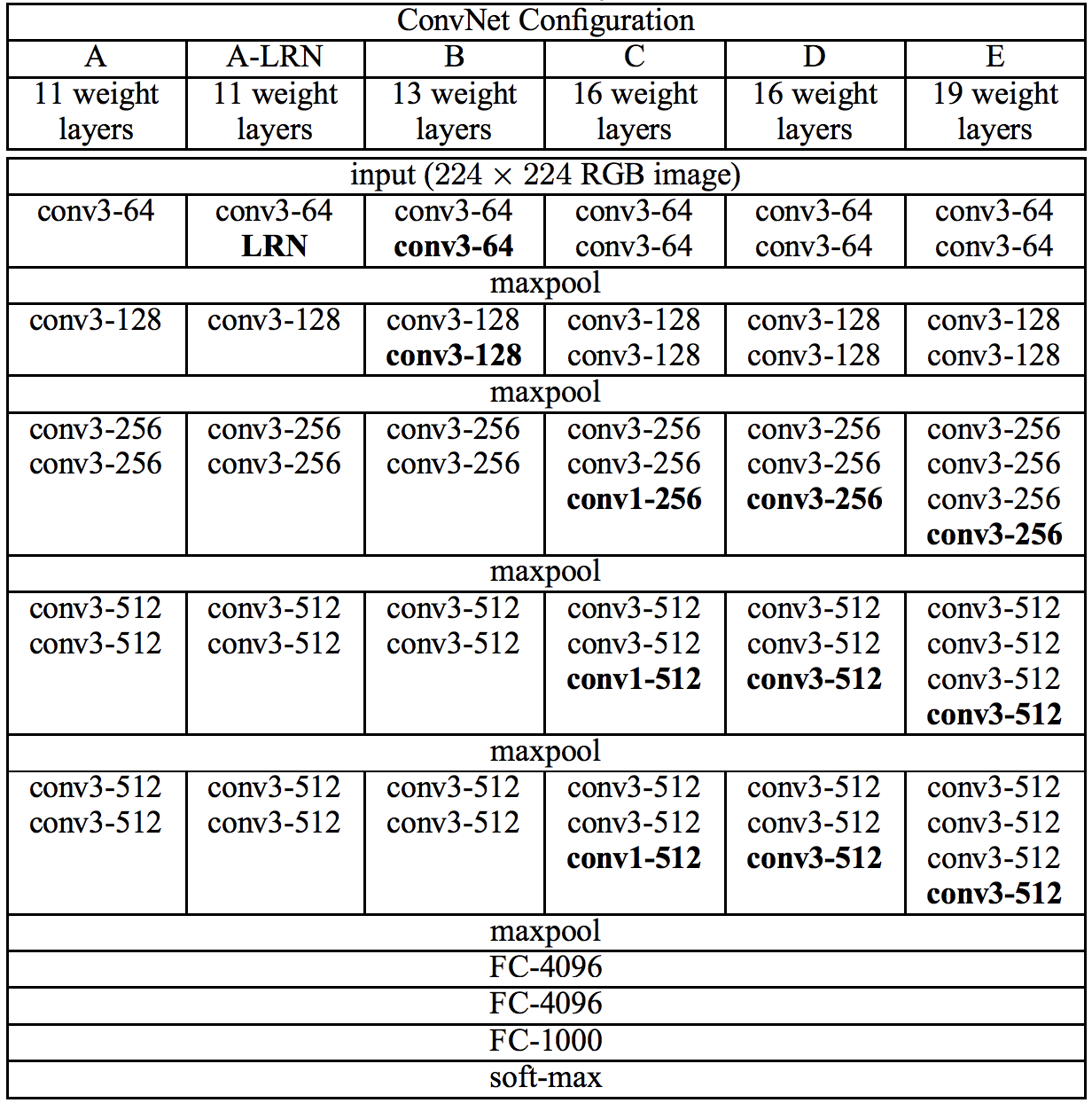
Fig. 3.3 VGGNet アーキテクチャ。Simonyan et al.[^vggnet] Table 1 より転載。#
次に、層数を増やすことで分類性能がどのように変化するかを調査するため、13 層のアーキテクチャ(VGG13)を構築しました。その結果、層数を増やすことで性能が向上することが確認されました。この時期には、1×1 の畳み込み(1×1 Convolution) を導入することで、非線形性を増やし、モデルの表現力を向上させられるという知見が得られていました。そのため、研究チームは 16 層の深層アーキテクチャに 1×1 Convolution を組み込んだモデル(VGG16 (Conv1))と、それを含まないモデル(VGG16)を比較しました。しかし、1×1 Convolution を含むモデルの効果は見られず、最終的には 1×1 Convolution を組み込まない VGG16 を採用しました。
さらに、層数を増やした 19 層のアーキテクチャ(VGG19)も構築し、実験を行いました。結果として、VGG16 と VGG19 が最も高い性能を示した。VGGNet の成功は、深層化が性能向上に重要であることを示し、深層学習アーキテクチャの設計における層数の役割を明らかにしました。
3.1.4. GoogLeNet#
GoogLeNet 4(または Inception)は、VGGNet とは独立に開発されたアーキテクチャで、2014 年の画像分類チャレンジ ISLVRC で 1 位を獲得しました。このモデルは、AlexNet や ZFNet などの従来のアーキテクチャとは異なり、革新的な技術を多数取り入れている点で注目されました。特に、1×1 畳み込み(1×1 Convolution)やグローバル平均プーリング(global average pooling)、そして特徴的な Inception モジュールが導入され、画像分類の精度向上に寄与しました。
当時、層を深くしたり、各層のユニット数を増やしたりすることで、モデルの分類性能を向上させられることが知られていました。しかし、層数やユニット数を増やすと過学習のリスクが高まり、計算コストも増大するという問題がありました。また、従来のアーキテクチャでは、畳み込み層が順次直列に接続されているため、層を深くするほど画像サイズが縮小し、表現力が制限されるという問題もありました。
この問題に対応するために、Inception モジュールが考案されました。このモジュールでは、1 つの入力画像に対して、異なるサイズの畳み込み層(1×1、3×3、5×5)を並列に適用し、それぞれの出力を連結することで、さまざまなスケールの特徴を同時に捉えることが可能になります(Fig. 3.4)。さらに、畳み込み処理の前に 1×1 畳み込みを挿入して特徴マップのチャンネル数を減らし、パラメーター数を削減する工夫がなされています。これにより、GoogLeNet は 22 層という深さを実現しつつ、モデルの効率性を維持することができました(Fig. 3.5)。
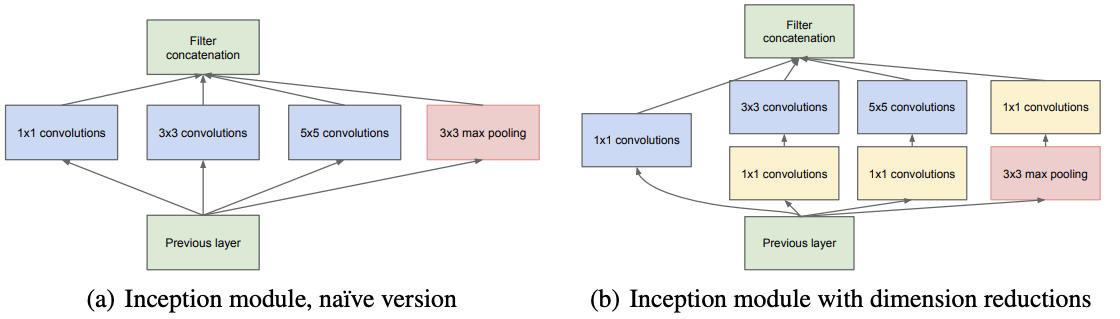
Fig. 3.4 Inception モジュールのアーキテクチャ。Christian et al.[^inception] Figure 2 より転載。#
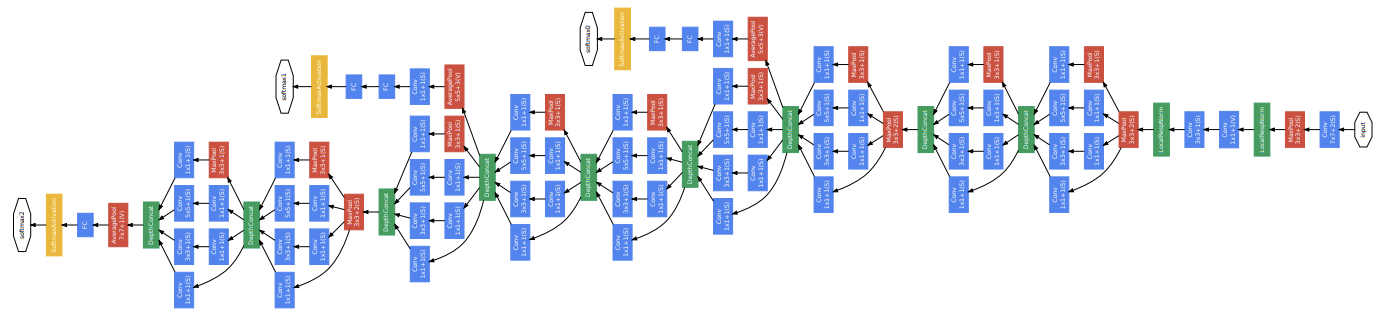
Fig. 3.5 Inception モジュールのアーキテクチャ。Christian et al.,[^inception] Figure 3 より転載。#
また、従来の画像分類アーキテクチャでは、最終層に全結合層を用いるのが一般的でした。しかし、全結合層は大量のパラメーターを必要とし、過学習を引き起こしやすいという問題がありました。これに対して、GoogLeNet では全結合層の代わりにグローバル平均プーリング(global average pooling)を採用しました。この技術では、最後の畳み込み層のチャンネル数を分類クラス数に一致させ、その各チャンネル内の画素値の平均を計算します。たとえば、分類クラスが 1,000 種類の場合、最後の畳み込み層で 1,000 チャンネルを生成し、それぞれのチャンネルで平均を計算して 1,000 次元のベクトルを得ます。このベクトルにソフトマックス関数を適用することで、各クラスの確率を算出し、分類結果を出力します。
GoogLeNet の登場は、深層学習のアーキテクチャ設計に新たな方向性を示しました。Inception モジュールによる計算効率の向上と多スケールの特徴抽出、グローバル平均プーリングによるパラメーター削減など、数多くの革新が導入されています。このアーキテクチャは後続のモデルに多大な影響を与え、Inception シリーズとしてさらに改良が重ねられていきました。
3.1.5. Inception v2/v3/v4#
GoogLeNet の成功を受けて、多くの改良が施された進化版が次々と登場しました。特に、Inception v2、Inception v3、Inception v4 はそれぞれ独自の改善を加え、深層学習モデルの性能向上に大きく貢献しました。また、ResNet のアイデアを取り入れた Inception-ResNet も開発されました。
Inception v2 6 では、計算コストが高い 5×5 の畳み込みを、連続する 3×3 の畳み込みに分解する Factorized Convolution を導入し、計算効率を向上させるとともに、パラメーター数を削減しました。さらに、各層の出力を正規化する バッチ正規化(Batch Normalization) を採用することで、学習の安定性が向上し、より深いネットワークの学習が可能となりました。
Inception v3 は、Inception v2 の改良版であり、いくつかの新しい技術が取り入れられています。まず、最適化アルゴリズムとして RMSProp を採用し、学習率を自動的に調整することで、勾配消失や発散を防ぎつつ、収束を加速させました。さらに、計算効率を向上させるために、畳み込み演算を分解する 非対称因子分解(Asymmetric Factorization) が導入され、例えば 3×3 の畳み込みを 1×3 と 3×1 に分割して計算する手法が採用されました。また、Label Smoothing という技術も追加され、これはモデルが特定のラベルに過度に適応するのを防ぐため、正解ラベルの確率分布をわずかにスムージングするものです。この方法により、モデルの汎化性能が向上し、過学習を防ぐ効果があります。さらに、Auxiliary Classifiers という中間層に補助的な分類器を追加する手法も採用され、これにより勾配消失問題が緩和され、全体の学習が安定しました。これらの改良によって、Inception v3 はより効率的で高精度なモデルとなり、多くの画像認識タスクで優れた性能を発揮するようになりました。
Inception v4 11 では、Inception モジュールの設計がさらに最適化され、さまざまなサイズの畳み込みやプーリングを組み合わせることで、より高い分類性能を実現しました。また、Inception-ResNet 11 と呼ばれるバージョンでは、Inception モジュールに ResNet のスキップ接続を統合しました。このスキップ接続により、非常に深いネットワークでも勾配消失を防ぎ、効率的な学習が可能になりました
3.1.6. ResNet#
ResNet(Residual Networks)1 は、Microsoft の He らの研究チームによって開発されたアーキテクチャです。残差学習(residual learning)という新しいアプローチを導入することで、層を 152 層まで深くしても高い性能を維持でき、2015 年の画像分類コンテストILSVRCで優勝しました。
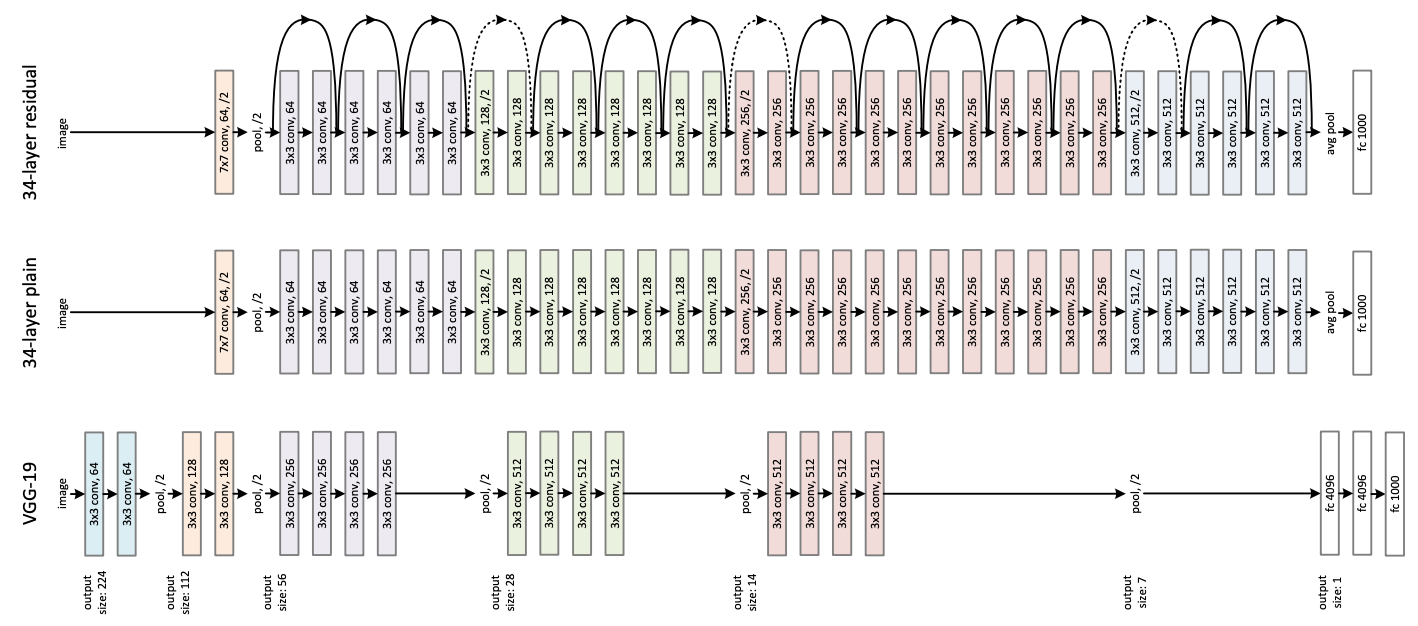
Fig. 3.6 ResNet のアーキテクチャ。He et al. Figure 3 より転載。#
深層学習において、ネットワークの層を深くすることで画像分類の性能が向上することは広く知られていましたが、層が一定の深さを超えると性能が逆に悪化することが明らかになりました。これは、出力層とラベルから算出される誤差がネットワーク内で後ろから前に伝播する際、後ろの層から前の層に進むにつれて誤差が小さくなり、入力層に近い層の学習が遅くなる「勾配消失問題」が発生するためです。
一般的なネットワークでは、例えば、ある層において、入力データ \(\mathbf{x}\) に対して関数 \(\mathbf{H}\) で変換し、出力として \(\mathbf{y}\) を得ます。数式で表すと次のようになります。
ネットワークの学習は、最適な関数 \(\mathbf{H}\) のパラメータを見つけることです。これに対して、残差学習では、入力 \(\mathbf{x}\) と出力 \(\mathbf{y}\) の差に着目します。その差を \(\mathbf{F}\) とおき、次式で表します。
このとき、
となり、ネットワークの学習では最適な関数 \(\mathbf{F}\) のパラメータを見つけることとなります。これにより、一般的な学習も残差学習も実質的には \(\mathbf{y} = \mathbf{H}(\mathbf{x})\) における \(\mathbf{H}\) のパラメータを求めている点では同じですが、後者では入力 \(\mathbf{x}\) がそのまま次の層に流れるため、誤差逆伝播の際に、誤差 \(\mathbf{y} - \mathbf{x}\) が小さくなりにくく、勾配がネットワークの深い層にまでしっかり伝わりやすくなります。
ResNet では、残差学習を 1 つの「残差ブロック(residual block)」として組み込み、これをネットワーク全体に適用しています(Fig. 3.7)。例えば、ResNet-34 では、64 チャンネルの入力画像に対して 2 回の畳み込み演算を行い、64 チャンネルの出力を得るブロックが使用されます。一方、より深いネットワーク(ResNet-50/101/152)では、画像のチャンネル数を 1×1 の畳み込みで変換し、複数回の畳み込み演算を行った後、再度 1×1 の畳み込みでチャンネル数を変換する方法を採用しています。これにより、層が非常に深くても勾配消失問題を回避し、高いパフォーマンスを維持できます。

Fig. 3.7 残差ブロックのアーキテクチャ。#
3.1.6.1. MobileNet#
MobileNet 4 は、モバイルデバイスや組み込みデバイスのような計算リソースが限られた環境での利用を想定して設計された、軽量で効率的な深層学習アーキテクチャです。その主な目的は、計算コストを抑えつつ、優れた性能を発揮することにあります。
この軽量化を実現する鍵となるのが、Depthwise Separable Convolutions という独自の畳み込み操作です。通常の畳み込みは、空間方向とチャネル方向の演算を同時に行いますが、Depthwise Separable Convolutions ではこれを 2 つに分けます。まず、Depthwise Convolution で各入力チャネルごとに独立したフィルタを適用し、空間的な特徴を抽出します。次に、Pointwise Convolution で 1×1 の畳み込みを行い、チャネル間の情報を結合します。この分解により、計算量が通常の畳み込みと比較して大幅に削減され、モデルが軽量化されると同時に効率性も向上します。
MobileNet は軽量性を重視して設計されているため、表現力や学習可能な特徴の複雑さが制限されるという課題があります。そのため、非常に複雑なタスクや大規模なデータセットに対応する場合、ResNet や EfficientNet などの高度なモデルが必要になる場合があります。しかし、計算リソースが限られる環境では、MobileNet はその効率性を活かして優れた性能を発揮します。
さらに、MobileNet は進化を続けており、MobileNet V2 9 および MobileNet V3 3 といった複数のバージョンが開発されています。モバイル端末での画像認識や物体検出などに利用されています。
3.1.7. DenseNet#
DenseNet(Densely Connected Convolutional Networks)5 は、2017 年に発表されたアーキテクチャで、特徴的な層間の接続設計によって、表現力と効率性を向上させたモデルです。
DenseNet の中核となる要素は DenseBlock です。この DenseBlock には複数の畳み込み層が含まれており、通常のニューラルネットワークでは各層が直前の層の出力を入力として処理を進めますが、DenseBlock では異なります。DenseBlock において、各層は、それ以前のすべての層からの出力を入力として受け取り処理を行います(Fig. 3.8)。この密接な接続構造により、情報が効果的に浅い層から深い層へ伝播するため、勾配消失問題が緩和されます。また、より多様で表現力豊かな特徴を学習できるようになります。
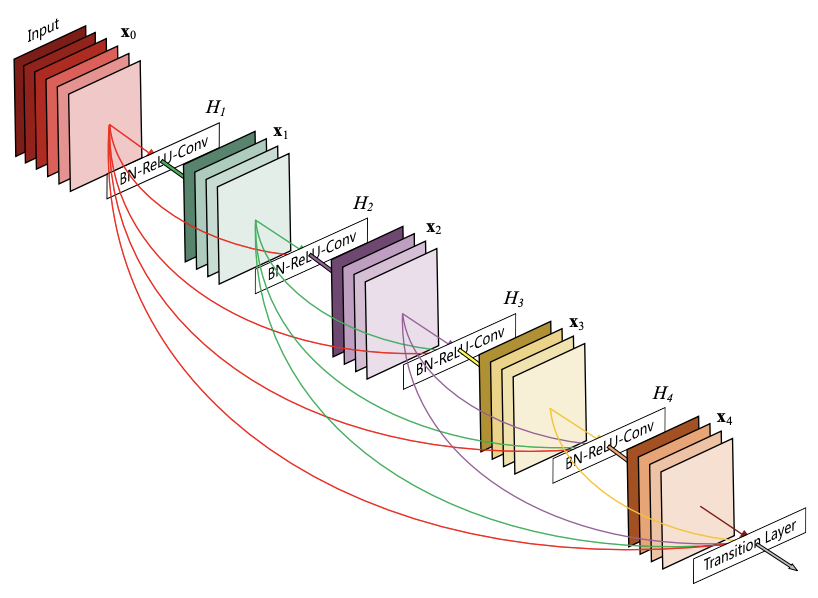
Fig. 3.8 DenseBlock のアーキテクチャ。 Huang et al.[^densenet] Figure 1 より転載。#
DenseBlock の間には Transition Layer が配置されています。この Transition Layer は、1×1 の畳み込みとプーリング操作を組み合わせて構成されています。この設計により、特徴マップのサイズを減少させ、ネットワークが深くなっても、計算コストを抑えることができるようになりました。
3.1.8. EfficientNet#
EfficientNet 13 は、2019 年に提案された深層学習アーキテクチャで、ネットワークの「深さ」「幅」「解像度」をバランスよく拡張することで、効率的かつ高性能なモデル設計を実現しました。このアーキテクチャは、MobileNet の軽量化設計の思想を従い EfficientNet-B0 を構築し、それを元に EfficientNet-B1 から B7 までのバリエーションが設計されています。各バリエーションでは、スケーリングパラメータを最適化し、ネットワークを段階的に拡大することで、モデルサイズや計算量を増やしながら精度を向上させています。これにより、従来のモデルと比較して圧倒的に少ないパラメータ数で高い精度を実現したアーキテクチャです。
EfficientNet は、その軽量性と効率性を活かし、計算リソースが制限されるモバイルデバイスやエッジデバイスでも優れた性能を発揮します。このアーキテクチャは、画像分類タスクで多くの従来モデルを凌駕する結果を達成しており、効率的な計算資源利用を重視するアプリケーションにおいて特に有用です。
3.1.9. 参照文献#
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: a large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, volume, 248–255. 2009. doi:10.1109/CVPR.2009.5206848.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), volume, 770–778. 2016. doi:10.1109/CVPR.2016.90.
Andrew Howard, Mark Sandler, Bo Chen, Weijun Wang, Liang-Chieh Chen, Mingxing Tan, Grace Chu, Vijay Vasudevan, Yukun Zhu, Ruoming Pang, Hartwig Adam, and Quoc Le. Searching for MobileNetV3 . In 2019 IEEE/CVF International Conference on Computer Vision (ICCV), volume, 1314–1324. Los Alamitos, CA, USA, November 2019. IEEE Computer Society. URL: https://doi.ieeecomputersociety.org/10.1109/ICCV.2019.00140, doi:10.1109/ICCV.2019.00140.
Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: efficient convolutional neural networks for mobile vision applications. 2017. URL: https://arxiv.org/abs/1704.04861, arXiv:1704.04861.
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q. Weinberger. Densely Connected Convolutional Networks . In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), volume, 2261–2269. Los Alamitos, CA, USA, July 2017. IEEE Computer Society. URL: https://doi.ieeecomputersociety.org/10.1109/CVPR.2017.243, doi:10.1109/CVPR.2017.243.
Sergey Ioffe and Christian Szegedy. Batch normalization: accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning - Volume 37, ICML'15, 448–456. JMLR.org, 2015.
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. Commun. ACM, 60(6):84–90, May 2017. URL: https://doi.org/10.1145/3065386, doi:10.1145/3065386.
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael S. Bernstein, Alexander C. Berg, and Li Fei-Fei. Imagenet large scale visual recognition challenge. CoRR, 2014. URL: http://arxiv.org/abs/1409.0575, arXiv:1409.0575.
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. MobileNetV2: Inverted Residuals and Linear Bottlenecks . In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), volume, 4510–4520. Los Alamitos, CA, USA, June 2018. IEEE Computer Society. URL: https://doi.ieeecomputersociety.org/10.1109/CVPR.2018.00474, doi:10.1109/CVPR.2018.00474.
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. 2015. URL: https://arxiv.org/abs/1409.1556, arXiv:1409.1556.
Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, and Alexander A. Alemi. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, AAAI'17, 4278–4284. AAAI Press, 2017.
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions . In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), volume, 1–9. Los Alamitos, CA, USA, June 2015. IEEE Computer Society. URL: https://doi.ieeecomputersociety.org/10.1109/CVPR.2015.7298594, doi:10.1109/CVPR.2015.7298594.
Mingxing Tan and Quoc V. Le. Efficientnet: rethinking model scaling for convolutional neural networks. 2020. URL: https://arxiv.org/abs/1905.11946, arXiv:1905.11946.