3.2. 演習:CNN 設計#
PyTorch や TensorFlow といった深層学習ライブラリの登場により、複雑なニューラルネットワークも簡潔なコードで設計できるようになりました。本節では、インストールが簡単でかつ使い方が簡易の PyTorch を利用して、画像分類を行うための畳み込みニューラルネットワーク(convolutional neural network; CNN)のアーキテクチャを設計する方法を説明します。また、設計したニューラルネットワークに対して、訓練および検証を行い、そして推論に用いる一連の流れを示します。
3.2.1. 準備作業#
3.2.1.1. ライブラリ#
CNN のアーキテクチャ設計や訓練などに必要なライブラリを読み込みます。機械学習関連のライブラリでは、PyTorch(torch)をアーキテクチャの設計や訓練に利用し、torchvision を画像データの前処理に利用し、scikit-learn(sklearn)をモデルの性能評価に利用します。また、NumPy、Pandas および Matplotlib などのライブラリは、モデルの性能や推論結果などの可視化に利用します。
# visualization
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import PIL.Image
# machine learning, deep learning
import sklearn.metrics
import torch
import torchvision
print(f'torch v{torch.__version__}; torchvision v{torchvision.__version__}')
torch v2.8.0+cu126; torchvision v0.23.0+cu126
ライブラリの読み込み時に ImportError や ModuleNotFoundError が発生した場合は、該当するライブラリをインストールしてください。ライブラリのバージョンを揃える必要はありませんが、PyTorch(torch)および torchvision が上記のバージョンと異なる時、実行中に警告メッセージが現れたり、同じ結果にならなかったりする可能性があります。
また、Google Colab を利用している場合は、メニューから「Runtime」→「Change runtime type」を選び、「Hardware accelerator」を GPU(例: T4 GPU や A100 GPU など)に設定することで、GPU を利用できるようになります。なお、ランタイムを変更すると、Google Colab が再起動されるので、上のコードをもう一度実行する必要があります。
3.2.1.2. データセット#
本節では OCT2017[1] を使用します。このデータセットは、光干渉断層撮影(optical coherence tomography; OCT)で撮影された網膜の画像を、健康(NORMAL)、加齢黄斑変性による脈絡膜新生血管(choroidal neovascularization; CNV)、糖尿病黄斑浮腫(diabetic macular edema; DME)、および網膜色素上皮の機能低下により生じるドルーゼン(DRUSEN)の 4 つのカテゴリに整理されています(Fig. 3.11)。
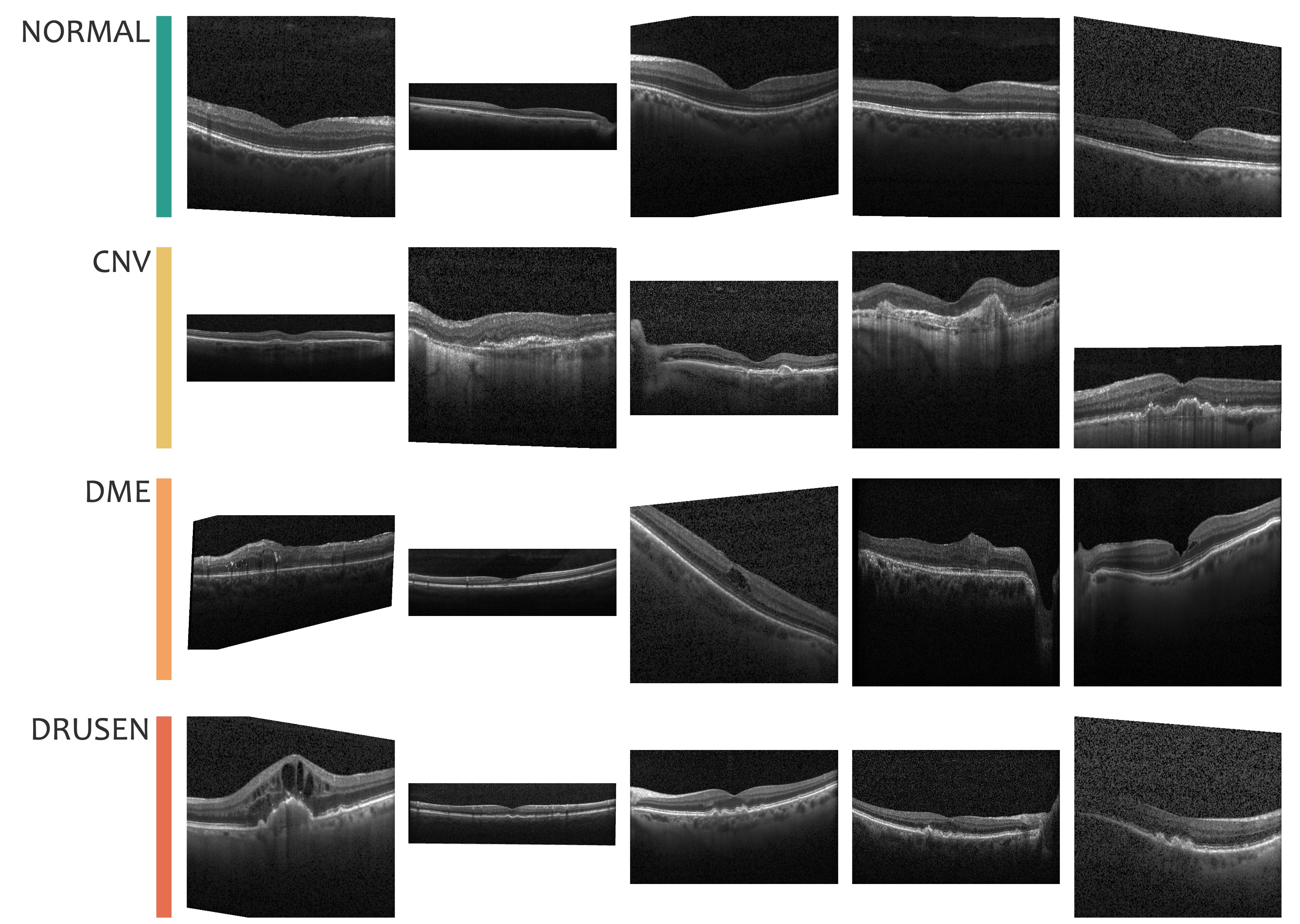
Fig. 3.9 OCT2017 データセットに含まれる各カテゴリのサンプル画像。#
OCT2017 データセットは、CC-BY 4.0 ライセンスのもと、Mendeley Data で公開されており、著作権表示を行うことで自由に利用できます。オリジナルデータセットは大きいため、本節では、オリジナルのデータセットから 1,200 枚の画像をランダムに抽出して作成した小規模なデータセットを使用します。本節で利用するデータセットは、Jupyter Notebook 上では、次のコマンドを実行することでダウンロードできます。
!wget https://dl.biopapyrus.jp/data/oct2017.zip
!unzip oct2017.zip
このデータセットは、訓練、検証、およびテストの 3 つのサブセットで構成されています。訓練サブセットには各カテゴリに 200 枚の画像が含まれています。また、検証およびテストサブセットには、それぞれ各カテゴリごとに 50 枚の画像が含まれています。
3.2.2. アーキテクチャ設計#
画像分類を行うために、CNN のアーキテクチャを設計します。このアーキテクチャは、画像を入力として受け取り、特徴を抽出する部分と、その特徴を用いて分類を行う部分の 2 つのモジュール(部品)に分かれています。特徴抽出モジュール(features)では、畳み込み演算(Conv2d)と最大プーリング演算(MaxPool2d)を 3 回繰り返す設計にしています。一方、分類モジュール(classifier)は、2 層の全結合層(Linear)で構成されるニューラルネットワークとなっています。画像データが入力された際に、まず特徴抽出モジュールにデータを渡し、その結果をさらに分類モジュールに渡して分類結果を出力するように、モジュール同士を接続します。
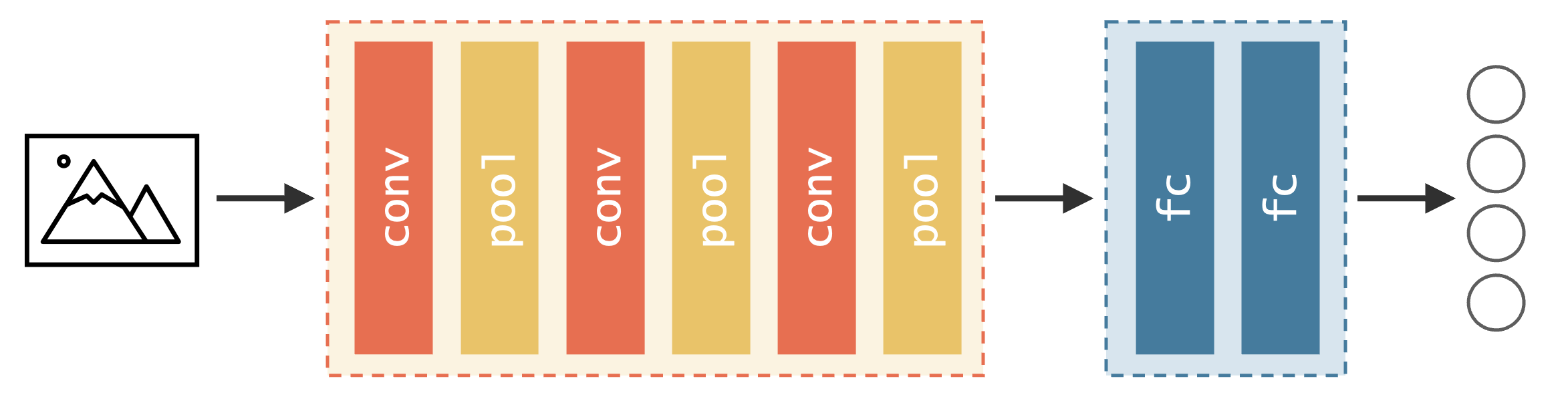
Fig. 3.10 アーキテクチャの設計図#
PyTorch では、torch.nn.Module クラスを継承し、__init__ メソッドの中で、モジュールを定義します。また、forward メソッドで、モジュールの繋ぎ合わせ順序を決めます。なお、畳み込み演算層および全結合層の計算結果を次の層に代入するときに、その間に ReLU 関数を使って非線形変換することが一般的であるため、本設計にも ReLU 関数(ReLU)を適用させます。
また、畳み込み層を中心とした特徴抽出モジュールの出力は、行列型のデータとなります。一方で、分類モジュールには、ベクトルを入力する必要があります。そのため、特徴抽出モジュールから出力される行列をベクトルに展開して、それを分類モジュールに代入できるように、分類モジュールの入力数を調整する必要があります。この入力数を自動で計算するためには、ダミーの画像を生成し(torch.zeros(1, 3, input_size, input_size))、それを特徴抽出モジュールに代入して、その計算結果を調べる処理を加えます(n_features = self.features(...))。
以上の処理を PyTorch でプログラム化すると、次のようになります。
class LiteCNN(torch.nn.Module):
def __init__(self, num_classes, input_size=224):
super().__init__()
self.features = torch.nn.Sequential(
torch.nn.Conv2d(3, 32, kernel_size=5),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Conv2d(32, 64, kernel_size=5),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Conv2d(64, 128, kernel_size=5),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2)
)
with torch.no_grad():
n_features = self.features(torch.zeros(1, 3, input_size, input_size)).numel()
self.classifier = torch.nn.Sequential(
torch.nn.Linear(n_features, 2048),
torch.nn.ReLU(),
torch.nn.Linear(2048, num_classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
3.2.3. 画像前処理#
訓練や推論に使用する画像のサイズが異なる場合、特徴抽出モジュールから出力される行列の大きさも異なります。一方で、アーキテクチャの設計において、特徴抽出モジュールと分類モジュールを接続する際、その接続数は固定されています。このため、入力画像のサイズを統一しないと、特徴抽出モジュールと分類モジュールの接続数が一致せず、ネットワーク全体が正常に動作しなくなります。
こうした問題を回避するには、入力する画像のサイズを統一する前処理が必要です。ここでは、入力画像を 224×224 ピクセルの正方形に変換する前処理関数(SquareResize)を定義します。
class SquareResize:
def __init__(self, shape=224):
self.shape = shape
def __call__(self, img):
return img.resize((self.shape, self.shape))
PyTorch で作られたニューラルネットワークにデータを入力する際、データをテンソル型に変換する必要があります。そこで、入力画像に対して、まずそのサイズを 224×224 ピクセルに変更し、次に画像をテンソル型に変化し、最後にデータを正規化する一連の変換処理(transform)を定義します。
transform = torchvision.transforms.Compose([
SquareResize(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.50, 0.50, 0.50],
[0.25, 0.25, 0.25])
])
画像データは通常、0 から 255 の範囲の整数値で表現されます。撮影対象によってチャンネルごとの値のスケールが異なる場合があります。例えば、青空を撮影した写真では青チャンネルの値が大きくなる一方で、緑や赤チャンネルの値は小さくなる傾向があります。このようなデータをニューラルネットワークにそのまま入力すると、勾配計算時に数値が発散したり、極端に小さくなったりする可能性があり、学習が適切に進まなくなる可能性があります。この問題を解決するために、各チャンネルごとに正規化を行います。正規化によって、各チャンネルの値が適切な範囲に収まり、勾配が安定することで学習が効率的に進むようになります。
3.2.4. モデル訓練#
アーキテクチャの設計図に基づいてモデルを生成します。設計図から生成された直後のモデルは、そのまま推論に使用することも可能だが、パラメータが乱数で初期化されているため、推論結果は完全にランダムなものになります。
model = LiteCNN(4, 224)
次のステップとして、訓練データをモデルに入力し、学習を繰り返すことで最適なパラメータを見つける作業を行います。まず、訓練データを読み込みます。また、モデルが訓練過程で過剰適合(過学習)を起こしていないか確認するため、訓練データを学習するたびにその成果を検証できるよう、検証データも併せて読み込みます。
train_dataset = torchvision.datasets.ImageFolder('oct2017/train', transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)
valid_dataset = torchvision.datasets.ImageFolder('oct2017/valid', transform=transform)
valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=32, shuffle=False)
モデルが訓練データを効率よく学習できるようにするため、損失関数、学習アルゴリズム、学習率、および学習率を調整するスケジュールを設定します。損失関数としては、分類問題で一般的に用いられる交差エントロピー損失(CrossEntropyLoss)を採用します。交差エントロピー損失は、モデルの出力する確率と実際のラベルを比較し、各カテゴリでの損失を合計して全体の損失とします。この仕組みにより、モデルが正解ラベルと同じカテゴリに対して 1.0 に近い値を出力し、その他のカテゴリに対して 0.0 に近い値を出力するほど、損失が小さくなります。
学習アルゴリズムは、モデルが最適解に到達する方法を決定するハイパーパラメータです。代表的なアルゴリズムとしては、Adam や SGD(確率的勾配降下法)などがあります。
学習率は、モデルが最適解に到達する速度を調節するための重要なハイパーパラメータです。適切な初期値を設定したうえで、スケジューラを利用して学習の進行に応じて学習率を動的に減少させたり、一定の周期で変化させたりする方法があります。このように学習率を調整することで、効率的に最適解を探索できます。本節では、学習の進行に応じて学習率を動的に減少させる方法を採用します。
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.00005)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
初期モデル、データ、および学習パラメータをすべて準備した後、モデルの訓練を開始します。訓練では、同じデータセットを 20 回(エポック)繰り返して学習させます。また、各エポックの学習後に検証データを用いてモデルの性能(正解率)を評価します。
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)
num_epochs = 20
metric_dict = []
for epoch in range(num_epochs):
# training phase
model.train()
running_loss = 0.0
n_correct_train = 0
n_train_samples = 0
for images, labels in train_loader:
images = images.to(device)
labels = labels.to(device)
# prediction
outputs = model(images)
# calculate loss and accuracy
loss = criterion(outputs, labels)
_, predicted_labels = torch.max(outputs.data, 1)
n_correct_train += torch.sum(predicted_labels == labels).item()
n_train_samples += labels.size(0)
running_loss += loss.item() / len(train_loader)
# learning from loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr_scheduler.step()
# validation phase
model.eval()
n_correct_valid = 0
n_valid_samples = 0
with torch.no_grad():
for images, labels in valid_loader:
images = images.to(device)
labels = labels.to(device)
# prediction
outputs = model(images)
# calculate validation accuracy
_, predicted_labels = torch.max(outputs.data, 1)
n_correct_valid += torch.sum(predicted_labels == labels).item()
n_valid_samples += labels.size(0)
# upadte training and validation losses and accuracies
metric_dict.append({
'epoch': epoch + 1,
'train_loss': running_loss,
'train_acc': n_correct_train / n_train_samples,
'valid_acc': n_correct_valid / n_valid_samples
})
print(metric_dict[-1])
Show code cell output
{'epoch': 1, 'train_loss': 1.4042848396301268, 'train_acc': 0.2625, 'valid_acc': 0.255}
{'epoch': 2, 'train_loss': 1.359282341003418, 'train_acc': 0.35125, 'valid_acc': 0.28}
{'epoch': 3, 'train_loss': 1.2745023345947268, 'train_acc': 0.4325, 'valid_acc': 0.275}
{'epoch': 4, 'train_loss': 1.167243137359619, 'train_acc': 0.505, 'valid_acc': 0.315}
{'epoch': 5, 'train_loss': 1.0062917876243591, 'train_acc': 0.60875, 'valid_acc': 0.325}
{'epoch': 6, 'train_loss': 0.8239109873771667, 'train_acc': 0.69875, 'valid_acc': 0.325}
{'epoch': 7, 'train_loss': 0.7776141262054443, 'train_acc': 0.72, 'valid_acc': 0.335}
{'epoch': 8, 'train_loss': 0.7436704802513123, 'train_acc': 0.74875, 'valid_acc': 0.35}
{'epoch': 9, 'train_loss': 0.7188391637802123, 'train_acc': 0.7475, 'valid_acc': 0.335}
{'epoch': 10, 'train_loss': 0.6919628572463988, 'train_acc': 0.75875, 'valid_acc': 0.345}
{'epoch': 11, 'train_loss': 0.6709359931945801, 'train_acc': 0.76875, 'valid_acc': 0.35}
{'epoch': 12, 'train_loss': 0.6676577091217041, 'train_acc': 0.7675, 'valid_acc': 0.35}
{'epoch': 13, 'train_loss': 0.6651109981536867, 'train_acc': 0.77, 'valid_acc': 0.345}
{'epoch': 14, 'train_loss': 0.6628077006340027, 'train_acc': 0.77, 'valid_acc': 0.35}
{'epoch': 15, 'train_loss': 0.6607417511940002, 'train_acc': 0.7675, 'valid_acc': 0.355}
{'epoch': 16, 'train_loss': 0.6584852099418639, 'train_acc': 0.76875, 'valid_acc': 0.355}
{'epoch': 17, 'train_loss': 0.6582863664627078, 'train_acc': 0.77, 'valid_acc': 0.355}
{'epoch': 18, 'train_loss': 0.6580597043037415, 'train_acc': 0.76875, 'valid_acc': 0.355}
{'epoch': 19, 'train_loss': 0.6578713846206665, 'train_acc': 0.77, 'valid_acc': 0.355}
{'epoch': 20, 'train_loss': 0.6576773452758791, 'train_acc': 0.76875, 'valid_acc': 0.355}
訓練データに対する損失と検証データに対する正解率を可視化し、訓練過程を評価します。
metric_dict = pd.DataFrame(metric_dict)
fig, ax = plt.subplots(1, 2)
ax[0].plot(metric_dict['epoch'], metric_dict['train_loss'])
ax[0].set_xlabel('epoch')
ax[0].set_ylabel('training loss')
ax[1].plot(metric_dict['epoch'], metric_dict['valid_acc'])
ax[1].set_ylim(0, 1)
ax[1].set_xlabel('epoch')
ax[1].set_ylabel('validation acc')
plt.tight_layout()
fig.show()
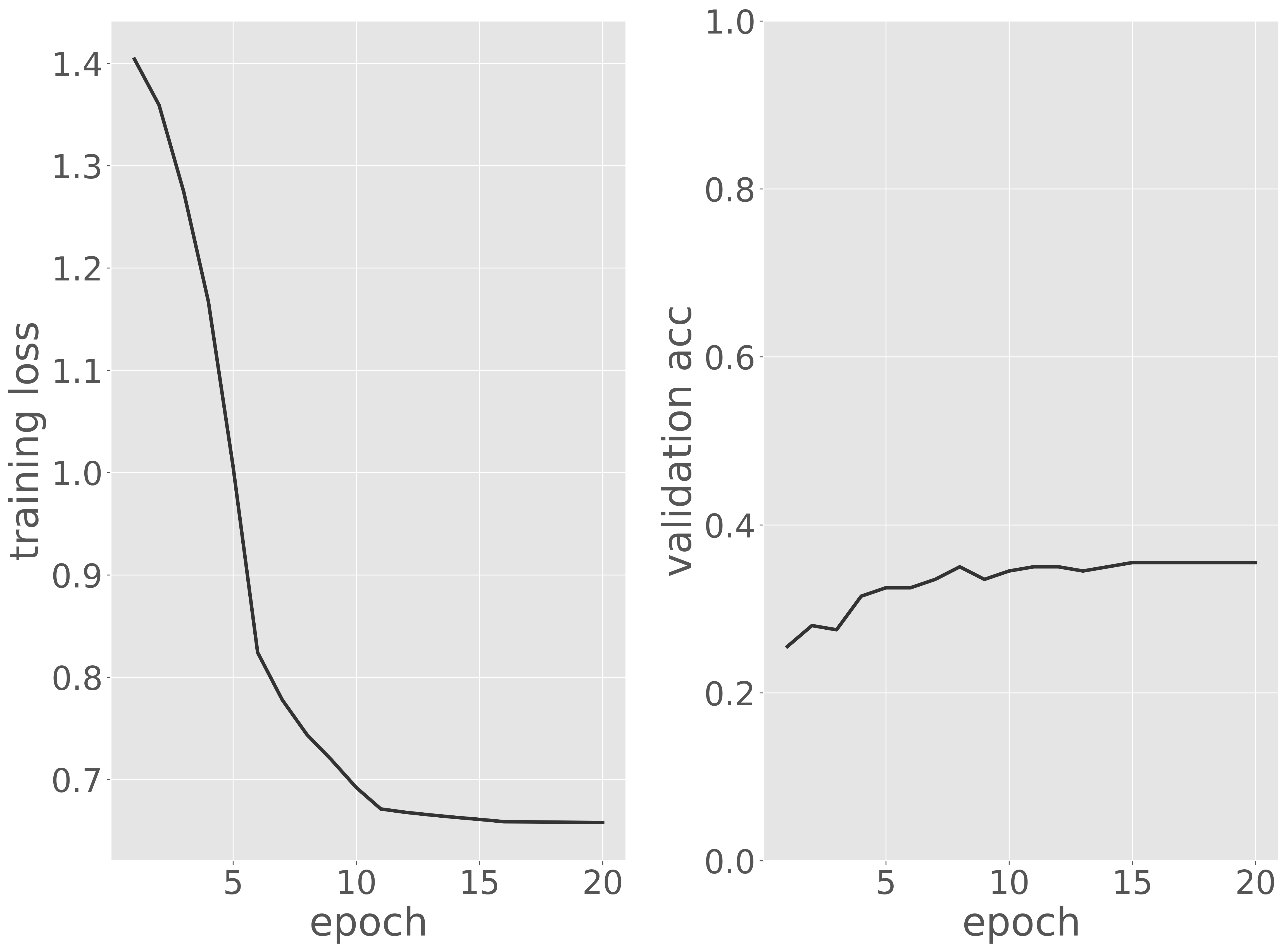
可視化の結果から、エポックが進むにつれて訓練データに対する損失が減少していることが確認できます。一方、検証データに対する正解率は、初めはランダムな値(4 クラスの場合は約 0.25)からスタートし、徐々に改善して 前後に到達しました。その後は大きな変動が見られず、更新が停止したことが分かります。
3.2.5. アーキテクチャ再設計#
検証の結果、予測性能(正解率)はランダムと比較して良好であるものの、十分な性能とは言えません。このため、訓練データを増やすことができない現状では、アーキテクチャを変更して性能の改善を図る必要があります[2]。たとえば、現在のアーキテクチャに畳み込み演算とプーリング演算のセットをもう 1 つ追加することで、検証性能がどのように変化するかを観察するのは有効です。このように、試行錯誤を重ねて性能向上を目指します。
class LiteCNN4Conv(torch.nn.Module):
def __init__(self, num_classes, input_size=224):
super().__init__()
self.features = torch.nn.Sequential(
torch.nn.Conv2d(3, 32, kernel_size=5),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Conv2d(32, 64, kernel_size=5),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Conv2d(64, 128, kernel_size=5),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Conv2d(128, 256, kernel_size=5),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2)
)
with torch.no_grad():
n_features = self.features(torch.zeros(1, 3, input_size, input_size)).numel()
self.classifier = torch.nn.Sequential(
torch.nn.Linear(n_features, 2048),
torch.nn.ReLU(),
torch.nn.Linear(2048, num_classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
model = LiteCNN4Conv(4, 224)
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.00005)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
num_epochs = 20
metric_dict = []
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
n_correct_train = 0
n_train_samples = 0
for images, labels in train_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
_, predicted_labels = torch.max(outputs.data, 1)
n_correct_train += torch.sum(predicted_labels == labels).item()
n_train_samples += labels.size(0)
running_loss += loss.item() / len(train_loader)
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr_scheduler.step()
model.eval()
n_correct_valid = 0
n_valid_samples = 0
with torch.no_grad():
for images, labels in valid_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted_labels = torch.max(outputs.data, 1)
n_correct_valid += torch.sum(predicted_labels == labels).item()
n_valid_samples += labels.size(0)
metric_dict.append({
'epoch': epoch + 1,
'train_loss': running_loss,
'train_acc': n_correct_train / n_train_samples,
'valid_acc': n_correct_valid / n_valid_samples
})
metric_dict = pd.DataFrame(metric_dict)
fig, ax = plt.subplots(1, 2)
ax[0].plot(metric_dict['epoch'], metric_dict['train_loss'])
ax[0].set_xlabel('epoch')
ax[0].set_ylabel('training loss')
ax[1].plot(metric_dict['epoch'], metric_dict['valid_acc'])
ax[1].set_ylim(0, 1)
ax[1].set_xlabel('epoch')
ax[1].set_ylabel('validation acc')
plt.tight_layout()
fig.show()
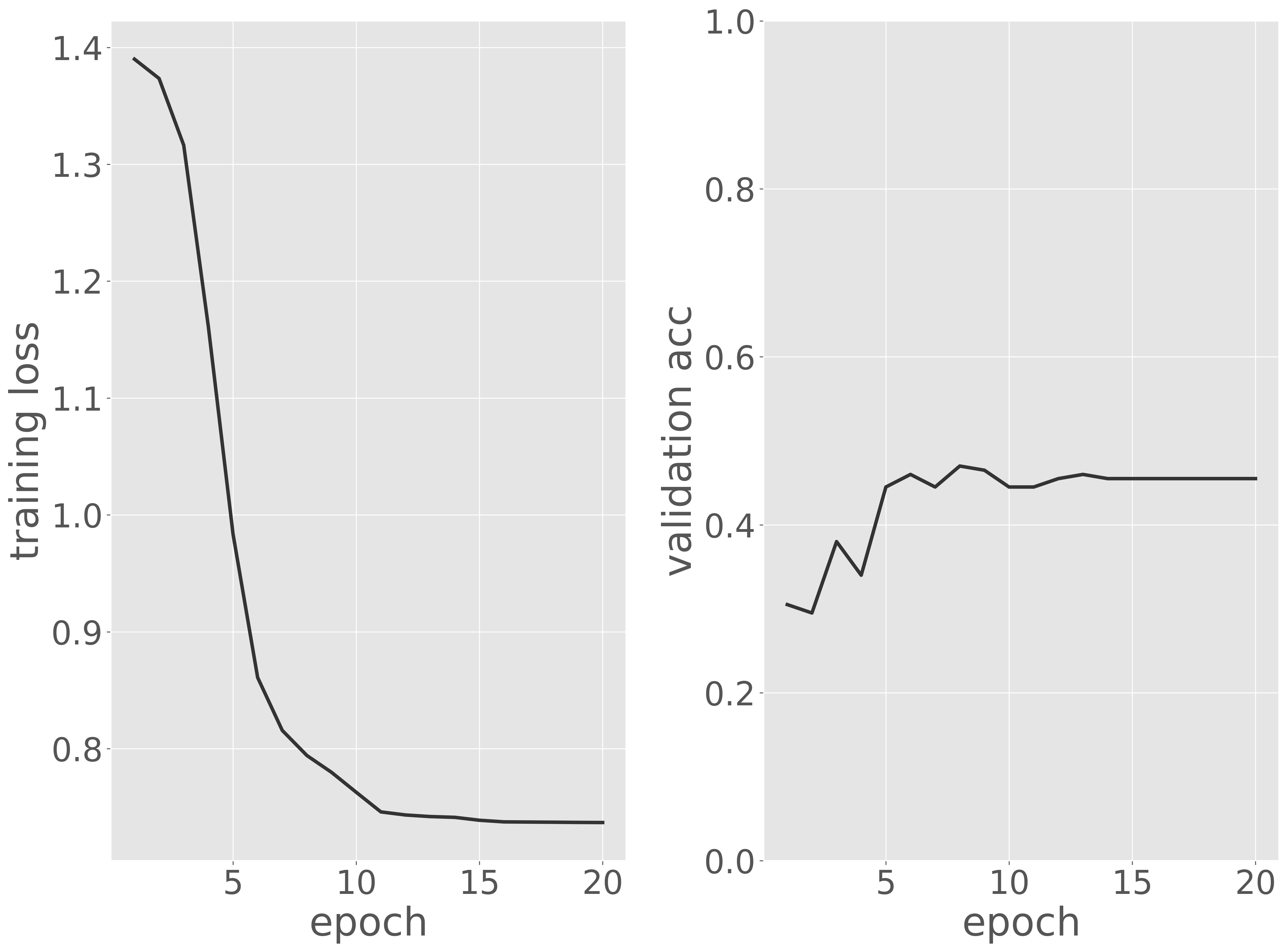
アーキテクチャを再設計した結果、予測性能を改善することができました。しかし、さらなる向上を達成するには、依然として多くの試行錯誤が必要です。
深層学習モデルのアーキテクチャは、ニューロンの構造や層の深さなどを柔軟に設計できる反面、最適な設計を見つけることは非常に困難です。また、モデルの訓練や検証には膨大な時間と計算リソースを要します。このため、特別な理由がない限り、ResNet や Inception などの既存のアーキテクチャを活用する方が、特に深層学習に詳しくない研究者にとっては現実的で効率的です。これらのアーキテクチャは専門家によって設計され、十分な検証を経ており、多くの分野で高い信頼性を持つとともに、研究や実用面でも非常に優れた成果を上げています。
3.2.6. 最適モデルの構築#
様々なアーキテクチャに対して訓練と検証を繰り返し、検証性能の指標を比較することで、最適なアーキテクチャを選定します。例えば、これまでのプロセスで LiteCNN と LiteCNN4Conv を比較した結果、LiteCNN4Conv が最適なアーキテクチャであると判断できたとします。この次のステップでは、モデル(アーキテクチャ)の選択に使用した訓練データや検証データとは別のデータを用いて、選定したアーキテクチャをさらに正確に評価する必要があります。そのために、まず訓練データと検証データを統合したデータセットを用いて、最適なアーキテクチャを改めて訓練し、最適モデルを構築します。
まず、訓練サブセットと検証サブセットを統合します。
!mkdir oct2017/trainvalid
!cp -r oct2017/train/* oct2017/trainvalid
!cp -r oct2017/valid/* oct2017/trainvalid
次にモデルの訓練を行います。最適なモデルを選択する段階で、5 エポック以降に予測性能がほぼ収束することがわかったので、ここでは訓練サブセットと検証サブセットを統合したデータに対して 5 エポックだけ訓練させます。
model = LiteCNN4Conv(4, 224)
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.00005)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
train_dataset = torchvision.datasets.ImageFolder('oct2017/trainvalid', transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)
num_epochs = 5
metric_dict = []
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
n_correct_train = 0
n_train_samples = 0
for images, labels in train_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
_, predicted_labels = torch.max(outputs.data, 1)
n_correct_train += torch.sum(predicted_labels == labels).item()
n_train_samples += labels.size(0)
running_loss += loss.item() / len(train_loader)
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr_scheduler.step()
metric_dict.append({
'epoch': epoch + 1,
'train_loss': running_loss,
'train_acc': n_correct_train / n_train_samples
})
print(metric_dict[-1])
Show code cell output
{'epoch': 1, 'train_loss': 1.3898060247302055, 'train_acc': 0.239}
{'epoch': 2, 'train_loss': 1.373247403651476, 'train_acc': 0.313}
{'epoch': 3, 'train_loss': 1.3273660317063332, 'train_acc': 0.364}
{'epoch': 4, 'train_loss': 1.240498524159193, 'train_acc': 0.429}
{'epoch': 5, 'train_loss': 1.0729311499744654, 'train_acc': 0.529}
訓練が完了したら、訓練済みモデルの重みをファイルに保存します。
model = model.to('cpu')
torch.save(model.state_dict(), 'LiteCNN4Conv.pth')
3.2.7. モデル評価#
最適なモデルが得られたら、次にテストデータを用いてモデルを詳細に評価します。正解率だけでなく、適合率、再現率、F1 スコアなどの評価指標を計算し、モデルを総合的に評価します。まず、テストデータをモデルに入力し、その予測結果を取得します。
# load model for validation
model = LiteCNN4Conv(4, 224)
model.load_state_dict(torch.load('LiteCNN4Conv.pth'))
model.to(device)
model.eval()
# load test data
test_dataset = torchvision.datasets.ImageFolder('oct2017/test', transform=transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=32, shuffle=False)
# validation
pred_labels = []
true_labels = []
with torch.no_grad():
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, _labels = torch.max(outputs.data, 1)
pred_labels.extend(_labels.cpu().detach().numpy().tolist())
true_labels.extend(labels.cpu().detach().numpy().tolist())
pred_labels = [test_dataset.classes[_] for _ in pred_labels]
true_labels = [test_dataset.classes[_] for _ in true_labels]
次に、予測結果とラベルを比較し、混同行列を作成します。これにより、間違いやすいカテゴリを特定することができます。
cm = sklearn.metrics.confusion_matrix(true_labels, pred_labels)
cm
array([[48, 2, 0, 0],
[15, 32, 1, 2],
[16, 29, 5, 0],
[ 0, 25, 9, 16]])
cmp = sklearn.metrics.ConfusionMatrixDisplay(cm, display_labels=valid_dataset.classes)
cmp.plot()
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7f93222b2910>
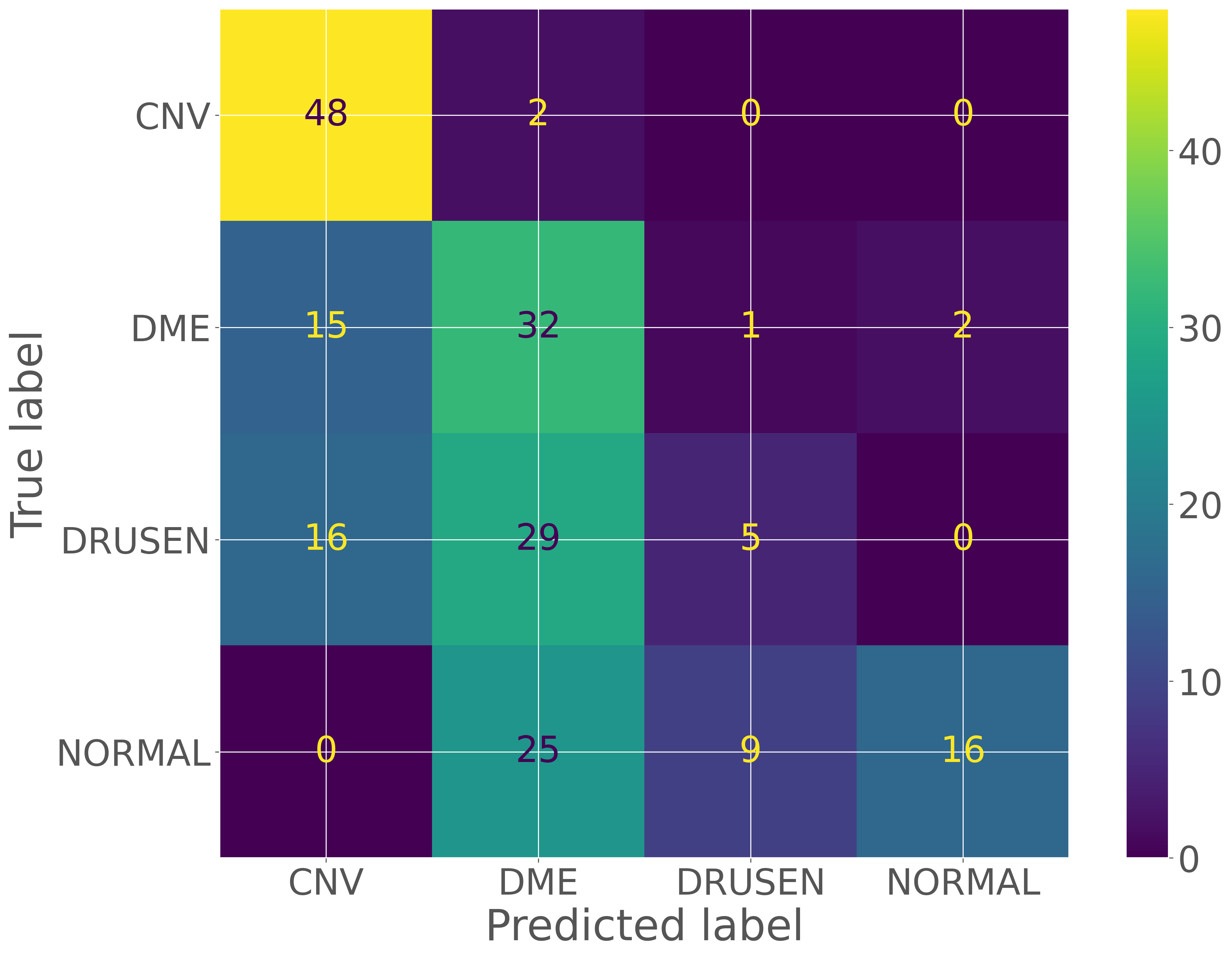
次に、各クラスにおける適合率、再現率、F1スコアなどの評価指標を計算します。
pd.DataFrame(sklearn.metrics.classification_report(true_labels, pred_labels, output_dict=True))
| CNV | DME | DRUSEN | NORMAL | accuracy | macro avg | weighted avg | |
|---|---|---|---|---|---|---|---|
| precision | 0.607595 | 0.363636 | 0.333333 | 0.888889 | 0.505 | 0.548363 | 0.548363 |
| recall | 0.960000 | 0.640000 | 0.100000 | 0.320000 | 0.505 | 0.505000 | 0.505000 |
| f1-score | 0.744186 | 0.463768 | 0.153846 | 0.470588 | 0.505 | 0.458097 | 0.458097 |
| support | 50.000000 | 50.000000 | 50.000000 | 50.000000 | 0.505 | 200.000000 | 200.000000 |
以上の評価結果を踏まえると、CNNアーキテクチャの特徴抽出モジュールに畳み込み層をもう 1 層追加して、さらに重要な特徴を抽出できるか試してみるのも良いでしょう。それでも改善が見られない場合は、誤分類されやすいカテゴリ同士でデータを増やし、再度モデルを構築するなどの対策を検討することが考えられます。
3.2.8. 推論#
推論を行う際には、訓練や評価時と同様に、アーキテクチャの設計図を基にモデルを生成します。ただし、ここで生成されたモデルのパラメータはランダムで設定されているため、次に load_state_dict 関数を使用して訓練済みのパラメータをモデルに展開する必要があります。
model = LiteCNN4Conv(4, 224)
model.load_state_dict(torch.load('LiteCNN4Conv.pth'))
model.to(device)
model.eval()
Show code cell output
LiteCNN4Conv(
(features): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1))
(4): ReLU()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(64, 128, kernel_size=(5, 5), stride=(1, 1))
(7): ReLU()
(8): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(9): Conv2d(128, 256, kernel_size=(5, 5), stride=(1, 1))
(10): ReLU()
(11): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=25600, out_features=2048, bias=True)
(1): ReLU()
(2): Linear(in_features=2048, out_features=4, bias=True)
)
)
次に polyps の画像を 1 枚選び、訓練時と同じ前処理を施します。その後、前処理をした画像をモデルに入力し、予測結果を表示させます。
labels = ['CNV', 'DME', 'DRUSEN', 'NORMAL']
image_path = 'kvasir/test/polyps/18a31930-8305-49a8-8bb4-1baf35da8c3e.jpg'
image = PIL.Image.open(image_path).convert('RGB')
input_tensor = transform(image).unsqueeze(0).to(device)
with torch.no_grad():
score = model(input_tensor)[0]
print(labels)
print(score)
['CNV', 'DME', 'DRUSEN', 'NORMAL']
tensor([ 7.3915, 0.7120, -1.7518, -5.7358], device='cuda:0')
このように、モデルの出力値は実数値として得られます。最も高い数値を持つクラスが予測結果(予測ラベル)となります。しかし、このままでは出力値が理解しにくいため、予測値を合計が 1.0 になるように、ソフトマックス関数を利用して正規化します。これにより、出力値を確率として解釈できるようになります。
prob = torch.softmax(score, axis=0).cpu().detach().numpy()
print(prob)
[9.9863654e-01 1.2546941e-03 1.0678551e-04 1.9873160e-06]
必要に応じて、Pandas などを使って出力結果を整形すると、より見やすくなります。
pd.DataFrame({
'class': labels,
'probability': torch.softmax(score, axis=0).cpu().detach().numpy()
})
| class | probability | |
|---|---|---|
| 0 | CNV | 0.998637 |
| 1 | DME | 0.001255 |
| 2 | DRUSEN | 0.000107 |
| 3 | NORMAL | 0.000002 |