4.1. 代表的なアーキテクチャ#
4.1.1. R-CNN#
R-CNN (Regions with CNN features) 3 は、物体検出のための深層学習アーキテクチャの一つです(Fig. 4.2)。R-CNN では、入力画像に対して selective search11 と呼ばれるアルゴリズムを適用し、物体が存在しそうな領域を約 2,000 個の候補として抽出します。次に、それぞれの候補領域を畳み込みニューラルネットワーク(CNN)に入力し、特徴を抽出します。抽出された特徴ベクトルは、最終的に サポートベクトルマシン(SVM) に入力され、物体の分類が行われます。
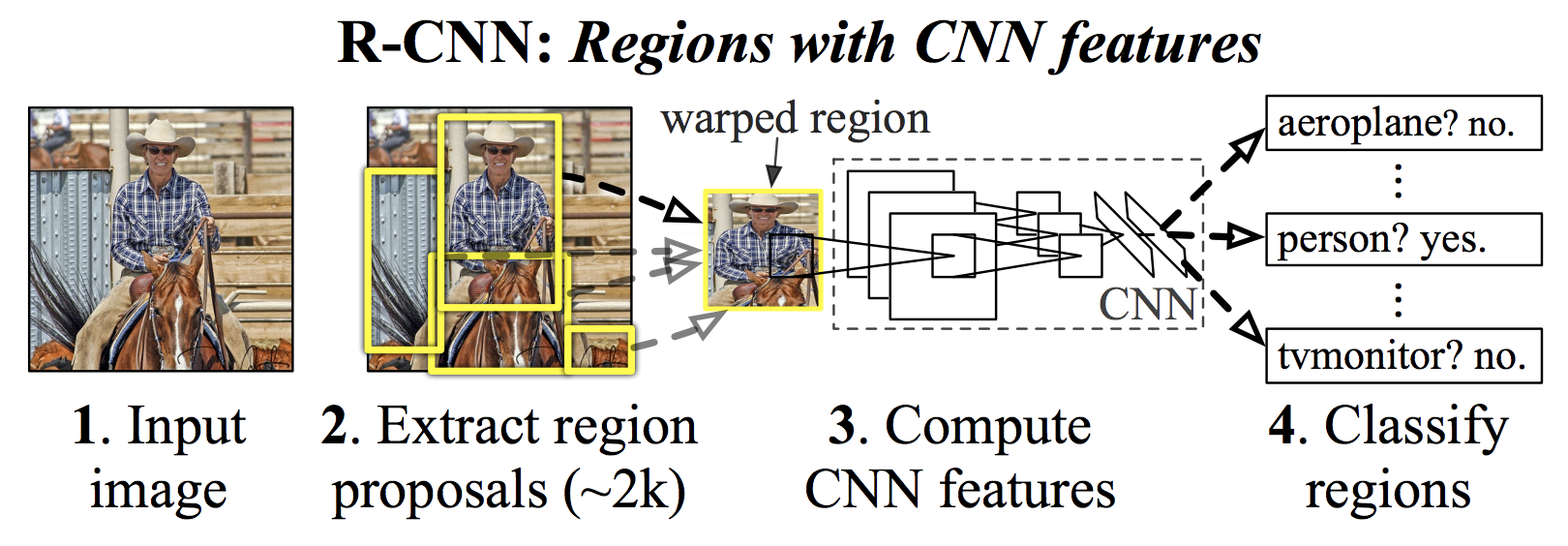
R-CNN は、従来の物体検出手法と比べて高い精度を達成しましたが、いくつかの課題もありました。第一に、学習および推論にかかる計算コストが非常に高く、リアルタイム処理や動画解析には適していませんでした。第二に、候補領域を生成する selective search は手作業で設計されたアルゴリズムであり、データセットごとに最適化できません。そのため、画像の特徴が変化した場合に適切な候補領域を見逃すリスクがありました。これらの課題を解決するために、後続の手法として Fast R-CNN2 や Faster R-CNN3 が開発され、処理速度と精度の両面で改良が加えられました。
4.1.2. Fast R-CNN#
Fast R-CNN2 は、物体検出のための深層学習アーキテクチャであり、R-CNN3 の改良版として提案されました。この手法は、R-CNN と同様に selective search11 を用いて物体候補領域(Regions of Interest; RoI)を生成し、それらを分類することで物体を検出します。しかし、R-CNN と比較して特徴量抽出の方法と処理の流れを効率化することで、大幅な速度向上を実現しています。
R-CNN では、各候補領域に対して個別に CNN を適用し特徴量を抽出していましたが、Fast R-CNN では、まず画像全体に対して一度だけ CNN を適用して convolution feature map を生成します(Fig. 4.3)。その後、各候補領域の特徴量をこの feature map から抽出し、バウンディングボックスの座標を予測するタスクと候補領域内の物体を分類するタスクを統一的に処理します。このアプローチにより、CNN を適用する回数を大幅に削減し、処理速度を劇的に改善することに繋がりました。
さらに、R-CNN が浅いニューラルネットワークを使用していたのに対し、Fast R-CNN では VGG16 などの深層ニューラルネットワークを採用することで、より表現力の高い特徴量を学習できるようになりました。これにより、精度面でも大きな改善が見られました。
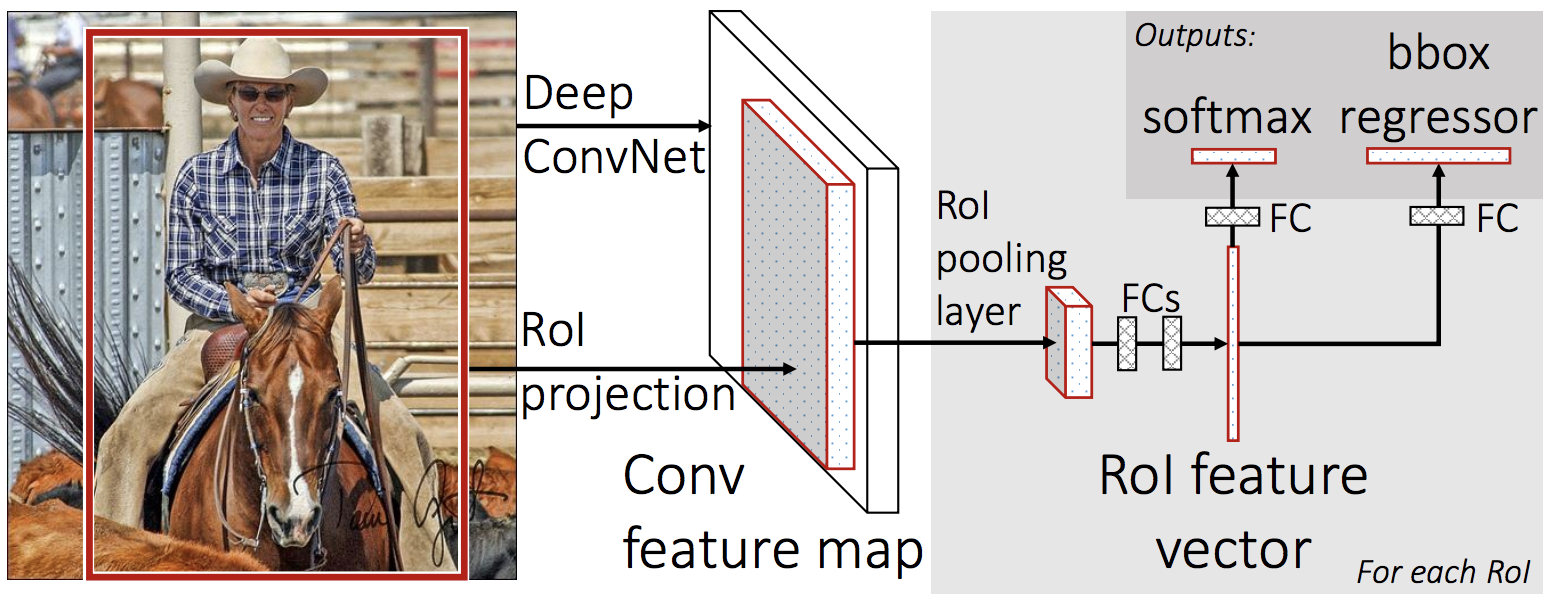
Fig. 4.3 Fast R-CNN のアーキテクチャ。Girshick et al2 Figure 1 より転載。#
4.1.3. Faster R-CNN#
Faster R-CNN 3 は、R-CNN 3 や Fast R-CNN 2 を改良した物体検出アルゴリズムです。これらの先行手法では、物体の候補領域を抽出するために selective search11 が使われていました。この処理は時間がかかり、物体検出アルゴリズム全体の処理時間のボトルネックとなっていました。これに対して、Faster R-CNN では、selective research を排除し、代わりに Region Proposal Network (RPN) を導入して、物体の位置検出とクラス分類の両方を CNN に統合しました。これにより、物体検出の速度を大幅に向上させることができました。
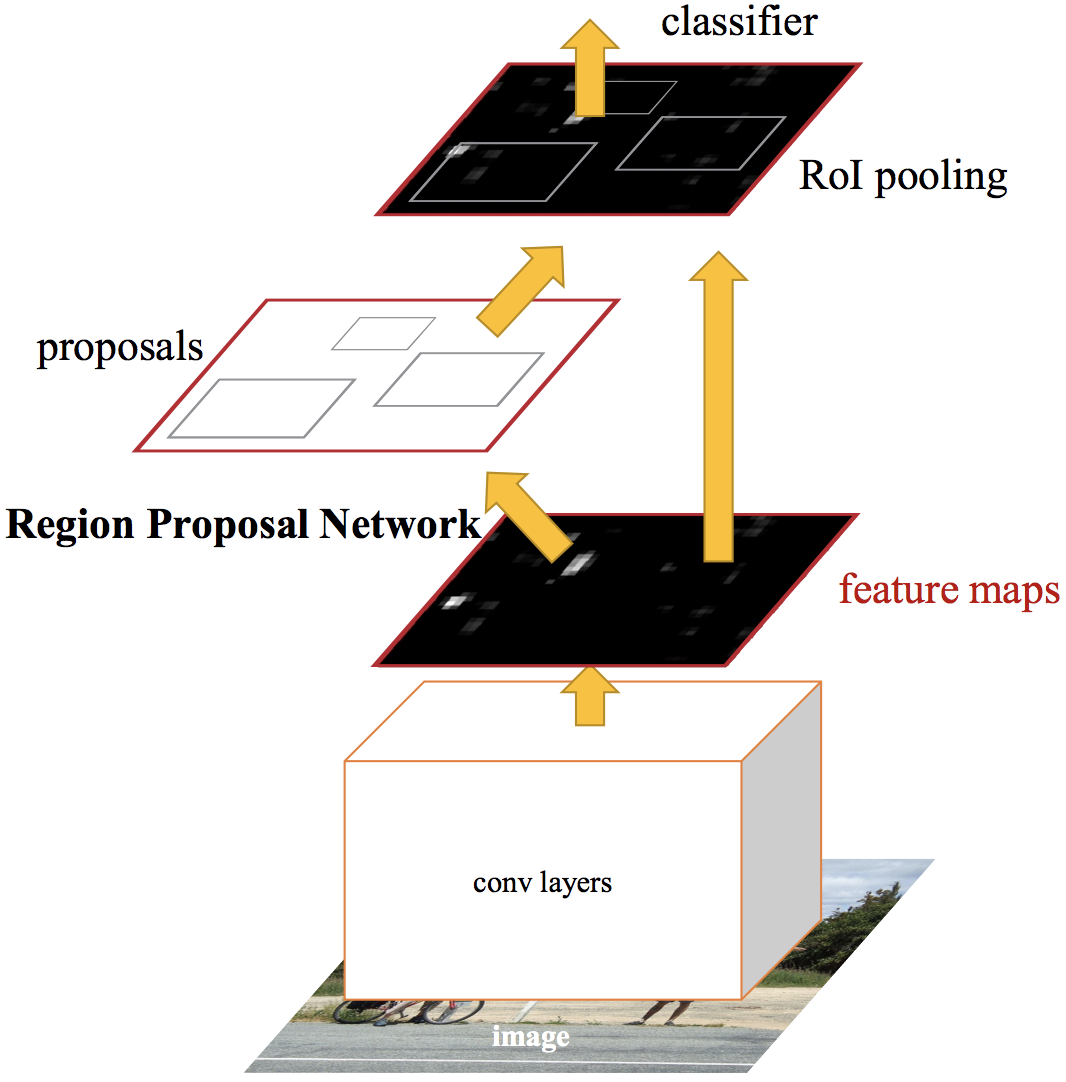
Faster R-CNN では、画像が入力されると、その画像を VGGNet や ResNet などの CNN に入力し、特徴マップ(feature maps)を得ます(Fig. 4.4)。次に、この特徴マップを Region Proposal Network (RPN) や RoI pooling 層に渡し、物体の場所や種類を推論します。
RPN では、特徴マップから物体の候補領域(バウンディングボックス)を推定します。具体的には、入力された特徴マップ全体に対して、小さな n×n のスライディングウィンドウを適用させます(Fig. 4.5)。各スライディングウィンドウの中央を基準点(アンカー)として、k 個の anchor box を生成します。次に、これらの anchor box に対して、分類層(cls 層)で anchor box の中に物体が含まれる確率(物体あり・なし)を推定します。同時に、回帰層(reg 層)において、より正確なバウンディングボックスを生成するように、anchor box の座標を調整します。
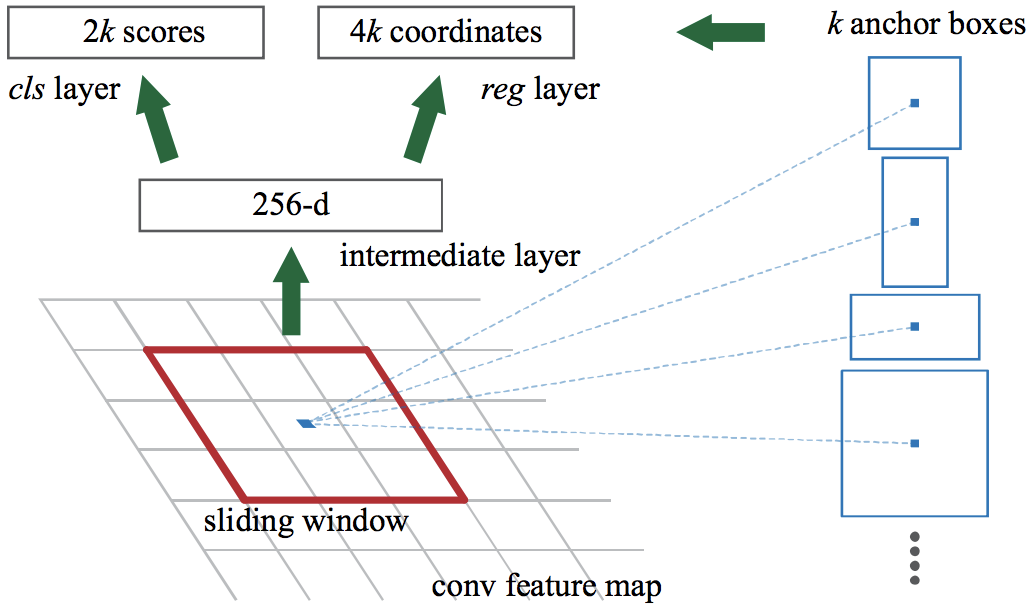
Fig. 4.5 Faster R-CNN アーキテクチャ中の Region Proposal Network (RPN) の処理。Ren et al3 Figure 3 より転載。#
RPN で生成された候補領域(バウンディングボックス)は、元の特徴マップとともに RoI pooling 層 に渡されます。この層では、候補領域を固定サイズ(例: 7×7)にリサイズし、全結合層に入力できる形式に変換します。この全結合層は、途中から二分岐し、片方がバウンディングボックスの座標を推定し、もう片方がバウンディングボックスに含まれる物体のクラスを推定するように出力が調整されます。
Faster R-CNN は、RPN を導入することで、物体の位置検出を CNN に統合し、処理速度を大幅に向上させました。PASCAL VOC1 や COCO5 などのベンチマークデータセットにおいて高い精度を達成し、物体検出の分野で標準的な手法の一つとなっています。
4.1.4. YOLO#
YOLO (You Only Look Once) 2 は、物体検出における代表的な one-stage method のアルゴリズムです。従来の R-CNN 系列の two-stage method とは異なり、YOLO は画像を一度に処理し、物体の位置とクラスを同時に推定します。画像全体を一度に処理することで、物体間の空間情報も活用できる点が特長です。この仕組みにより、YOLO は検出精度を高めるだけでなく、リアルタイム処理が求められる応用にも対応可能な速度を実現しています。
YOLO の処理では、まず入力画像を S×S のグリッドに分割します。次に、グリッドで分割された各領域(グリッドセル)に対して、あらかじめ設定された B 個のバウンディングボックス(anchor boxes)を割り当てます。各バウンディングボックスには、その領域に物体が含まれている確率(信頼スコア, \( P(\text{object}) \))と、バウンディングボックスの座標(中心座標、幅、高さ)を予測する役割があります。信頼スコアは、バウンディングボックス内に検出対象の物体が含まれている場合は 1.0、背景である場合は 0.0 に近い値を取るように学習されます。さらに、各グリッドセルにおいて、物体が存在すると仮定した場合にそれがどのカテゴリに属するかを示す条件付き確率 \( P(\text{class|object}) \) を計算します。この条件付き確率 \( P(\text{class|object}) \) と信頼スコア \( P(\text{object}) \) を掛け合わせることで、それぞれのバウンディングボックスがどのクラスに属する物体を含んでいるかを推定します。
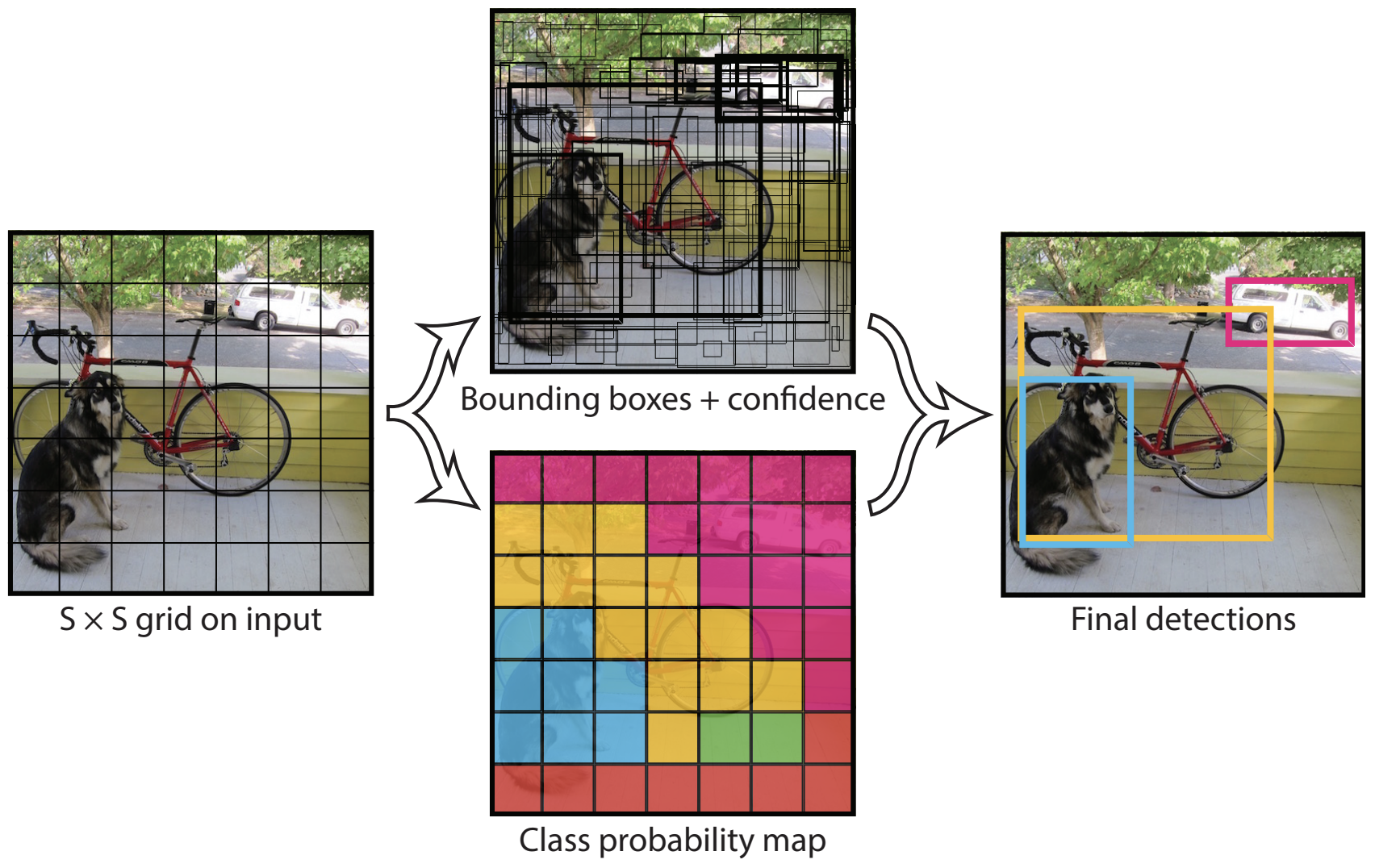
YOLO では、バウンディングボックスの座標、信頼スコア、そして分類時の条件付き確率が正解ラベルとどれだけ異なるかを計算し、これらを単一の損失関数にまとめて評価・最適化します。これにより、全ての予測を一括で行うことが可能となります。R-CNN 系で必要とされた候補領域の生成や特徴抽出といった段階的な処理が不要になり、実行速度を大幅に改善できました。
YOLO の初期バージョン(YOLOv1)は、シンプルなアーキテクチャながら、高速かつ高精度な物体検出を実現しました。しかし、小さな物体や重なっている複数の物体を検出するのが困難でした。これに対して、anchor boxes の導入や異なる解像度で物体を検出可能にするマルチスケール検出機能の追加などにより、検出性能の改善が図られました。
YOLO、YOLOv2 8 および YOLOv3 9 は、オリジナルの開発者である Joseph Redmon らによって発表されました。その後、Redmon は倫理的な懸念などから YOLO の開発を中止しました。しかし、その後も YOLO の名を冠した新たなバージョンのアーキテクチャが複数の研究者や団体によって開発されています。
YOLOv4 および YOLOv7 は、YOLO のベースフレームワークである Darknet を管理している Bochkovskiy らによって発表されました。YOLOv5、YOLOv8、YOLOv11 は、スペインの Ultralytics 社 によって開発され、PyTorch をベースに実装されています。YOLOv6 は、中国の Meituan(美団)社 によって発表され、主に産業用途での実用性を考慮して設計されました。YOLOv9 は、YOLOv4 や YOLOv7 に携わった研究者たちが開発しました。YOLOv10 は、清華大学の研究者グループによって開発され、新しいアーキテクチャが採用されています。
このように、YOLO の名称は共通ですが、各バージョンの開発元は異なり、使用されている技術や特徴、ライセンス形態も異なります。そのため、YOLO を利用する際は、性能や機能だけでなく、ライセンス条件についても事前に確認することが重要です。
4.1.5. SSD#
SSD (Single Shot MultiBox Detector)1 は、画像全体を一度に処理して、物体の位置(バウンディングボックス)とクラスを同時に推定する仕組みを採用しています。SSD は、YOLO に続く one-staeg method 代表的な手法の一つです。
SSD のアーキテクチャは、特徴マップを活用して物体を検出します。ベースとなる畳み込みニューラルネットワーク(例えば VGG16)が画像から特徴を抽出し、その後の畳み込み層で異なる解像度の特徴マップを生成します(Fig. 4.7)。これらのマップを用いて、異なるスケールの物体を検出可能にしています。具体的には、低解像度のマップは大きな物体の検出に、高解像度のマップは小さな物体の検出に適しています。また、各特徴マップ上で複数のデフォルトバウンディングボックス(default boxes)を事前に定義しており、各ボックスに対してクラスと位置を同時に予測します。

SSD は初期の YOLO と同様に、小さな物体や密集した物体を検出する場合、精度が低下する傾向があります。その後、いくつかの改良がなされ FSSD などが提案されました。
4.1.6. RetinaNet#
RetinaNet 4 は、物体検出の分野で one-stage method の性能を大きく向上させたアルゴリズムの一つです。従来、two-stage method は高い精度を実現する一方で処理速度が遅く、one-stage method は高速だが精度で劣るとされていました。RetinaNet は、Focal Loss と呼ばれる新しい損失関数を導入することで、one-stage method における精度の課題を克服し、速度と精度のバランスを大幅に改善しました。
RetinaNet のアーキテクチャは、画像から特徴を抽出するバックボーンネットワーク(例: ResNet)と、特徴マップの中で物体を検出するための Feature Pyramid Network (FPN) で構成されています。FPN により、異なる解像度の特徴マップを利用して、大きな物体から小さな物体まで効率的に検出することができます。これに加え、各特徴マップ上でアンカーボックス(anchor boxes)を使用して、物体の位置とクラスを同時に予測します。
RetinaNet の最大の特徴は、Focal Loss にあります。この損失関数は、one-stage method におけるクラス不均衡問題に対処するために設計されました。従来の損失関数では、検出対象物が少なく背景の例が圧倒的に多いため、検出が困難な小さな物体や曖昧な物体が見逃されることが多くありました。Focal Loss は、難しい例に重点を置き、簡単な例の影響を抑えることで、検出精度を大幅に向上させています。
4.1.7. 参照文献#
M. Everingham, S. M. A. Eslami, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The pascal visual object classes challenge: a retrospective. International Journal of Computer Vision, 111(1):98–136, January 2015.
Ross Girshick. Fast r-cnn. 2015. URL: https://arxiv.org/abs/1504.08083, arXiv:1504.08083.
Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In 2014 IEEE Conference on Computer Vision and Pattern Recognition, volume, 580–587. 2014. doi:10.1109/CVPR.2014.81.
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. 2018. URL: https://arxiv.org/abs/1708.02002, arXiv:1708.02002.
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: common objects in context. 2015. URL: https://arxiv.org/abs/1405.0312, arXiv:1405.0312.
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C. Berg. SSD: Single Shot MultiBox Detector, pages 21–37. Springer International Publishing, 2016. URL: http://dx.doi.org/10.1007/978-3-319-46448-0_2, doi:10.1007/978-3-319-46448-0_2.
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You Only Look Once: Unified, Real-Time Object Detection . In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), volume, 779–788. Los Alamitos, CA, USA, June 2016. IEEE Computer Society. URL: https://doi.ieeecomputersociety.org/10.1109/CVPR.2016.91, doi:10.1109/CVPR.2016.91.
Joseph Redmon and Ali Farhadi. Yolo9000: better, faster, stronger. 2016. URL: https://arxiv.org/abs/1612.08242, arXiv:1612.08242.
Joseph Redmon and Ali Farhadi. Yolov3: an incremental improvement. 2018. URL: https://arxiv.org/abs/1804.02767, arXiv:1804.02767.
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks . IEEE Transactions on Pattern Analysis & Machine Intelligence, 39(06):1137–1149, June 2017. URL: https://doi.ieeecomputersociety.org/10.1109/TPAMI.2016.2577031, doi:10.1109/TPAMI.2016.2577031.
J. R. Uijlings, K. E. Sande, T. Gevers, and A. W. Smeulders. Selective search for object recognition. Int. J. Comput. Vision, 104(2):154–171, September 2013. URL: https://doi.org/10.1007/s11263-013-0620-5, doi:10.1007/s11263-013-0620-5.