1.3. モデル評価#
機械学習の目標は、未知のデータに対して高い予測性能を発揮するモデルを構築することです。そのため、モデルの未知に対する予測性能を正確に評価には、訓練データと独立して収集した検証データを用いて評価する必要があります。しかし、特に医学を含む生命科学の分野において、データの再収集が難しい場合が多いです。そこで、すでに収集したデータを適切に訓練データと検証データなどに分割して、モデルの構築と評価に利用する方法がとられています。その代表的な方法として、ホールアウト法や k-分割交差検証法などがあります。
1.3.1. ホールドアウト法#
ホールドアウト法(hold-out validation)では、モデルの訓練を開始する前に、収集されたデータセットを訓練、検証、そしてテストの 3 つのサブセットに分割します(Fig. 1.1)。次に、訓練サブセットを利用して様々なモデルを構築します。この際、ロジスティック回帰やサポートベクトルマシン、ニューラルネットワークなど異なるアルゴリズムを用いてモデルを作成することもできますし、同じアルゴリズムを使いつつ特徴量やハイパーパラメーターを変えて複数のモデルを構築することも可能です。その後、検証サブセットを用いてこれらのモデルの性能を計算し、それぞれの検証性能を比較して最適なモデルを選択します。
最適なモデルが選択されると、次に訓練サブセットと検証サブセットを統合し、そのモデルを訓練し直します。その後、この統合データで訓練したモデルに対して、テストサブセットを用いてモデルの汎化性能を評価します。
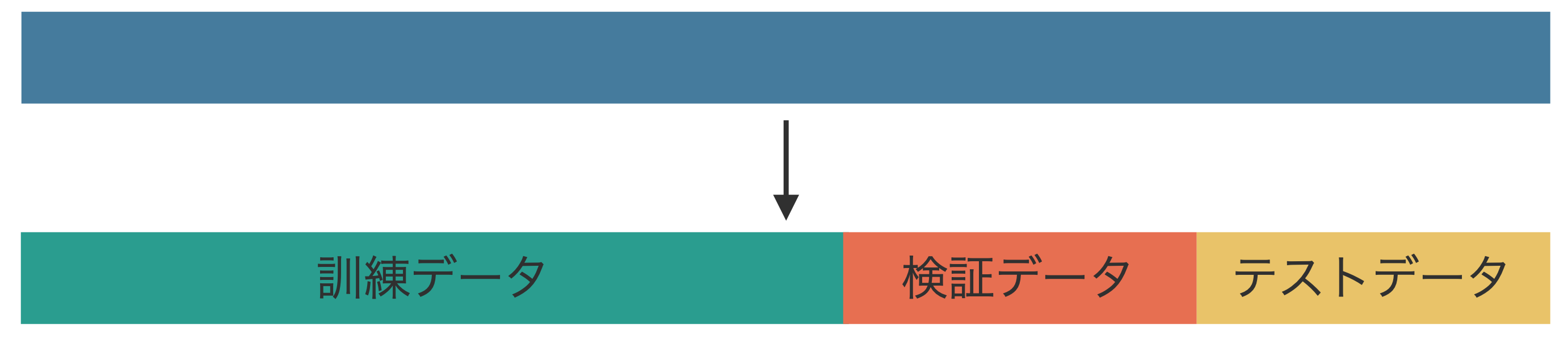
Fig. 1.1 ホールドアウト法ではデータを訓練、検証、テストの 3 つのサブセットに分割して、モデルの構築と評価に利用します。#
ここ注意するべきことは、最終的なモデルの性能は、検証サブセットに対する性能ではなく、テストサブセットで評価された性能で判断される点です。検証サブセットに対する性能は、複数のモデルの中で最適なモデルを選択する目的だけで利用します。言い換えれば、最適なモデルを選択できたら、検証サブセットの役割は終わりです。また、もし最初にモデルを 1 つしか作っていなければ、検証サブセットを用意する必要もありません。
また、訓練、検証、テストの 3 つのサブセットに分けるときの割合については、6:2:4 や 7:2:1 などのように訓練サブセットに含まれるサンプルが多くなるようにします。なお、サンプルを訓練サブセットに多く配分することで、モデルの訓練が十分に行われ、性能が高くなることが考えられるが、テストデータに配分するサンプルが少なくなり、十分な性能評価ができない可能性があります。しかし、逆にテストサブセットのサンプルを増やすために、訓練サブセットのサンプルを減らすと、モデルを十分に訓練できなくなる恐れがあります。この割合はデータに含まれるサンプルの数を見ながら決めます。
ホールアウト法の問題点として、収集されたサンプルの数が少ない場合は、3 つのサブセットに分けたとき、各サブセットに十分なデータが確保できなくなる可能性があります。これにより、訓練も不十分であり、評価も不正確になるリスクがあります。また、最適なモデル選択において、検証サブセットを利用しているために、最終的には「検証サブセットに最も適合するモデル」が選択されてしまうリスクもあります。これらの問題を対処するために、訓練サブセットと検証サブセットを入れ替えながら交互に検証を行なっていく k-分割交差検証法などの手法を用いることが推奨されます。
1.3.2. k-分割交差検証法#
k-分割交差検証法(k-fold crossvalidation)は、予測モデルの汎化性能を正確に検証するために用いられる手法です。k-分割交差検証では、すべてのデータを訓練およびテストサブセットに分けます(Fig. 1.2)。この比率はデータに含まれるサンプル数に応じて決めます。次に、訓練サブセットをさらに k 個のサブセットに等分割します。k は 5 または 10 がよく使われます。k 個のサブセットを作成したのちに、そのうち k - 1 個のサブセットを訓練に、残りの 1 つのサブセットを検証に利用するプロセスをすべての組み合わせに対して繰り返します。これにより、k 回の学習と評価が実行されます。
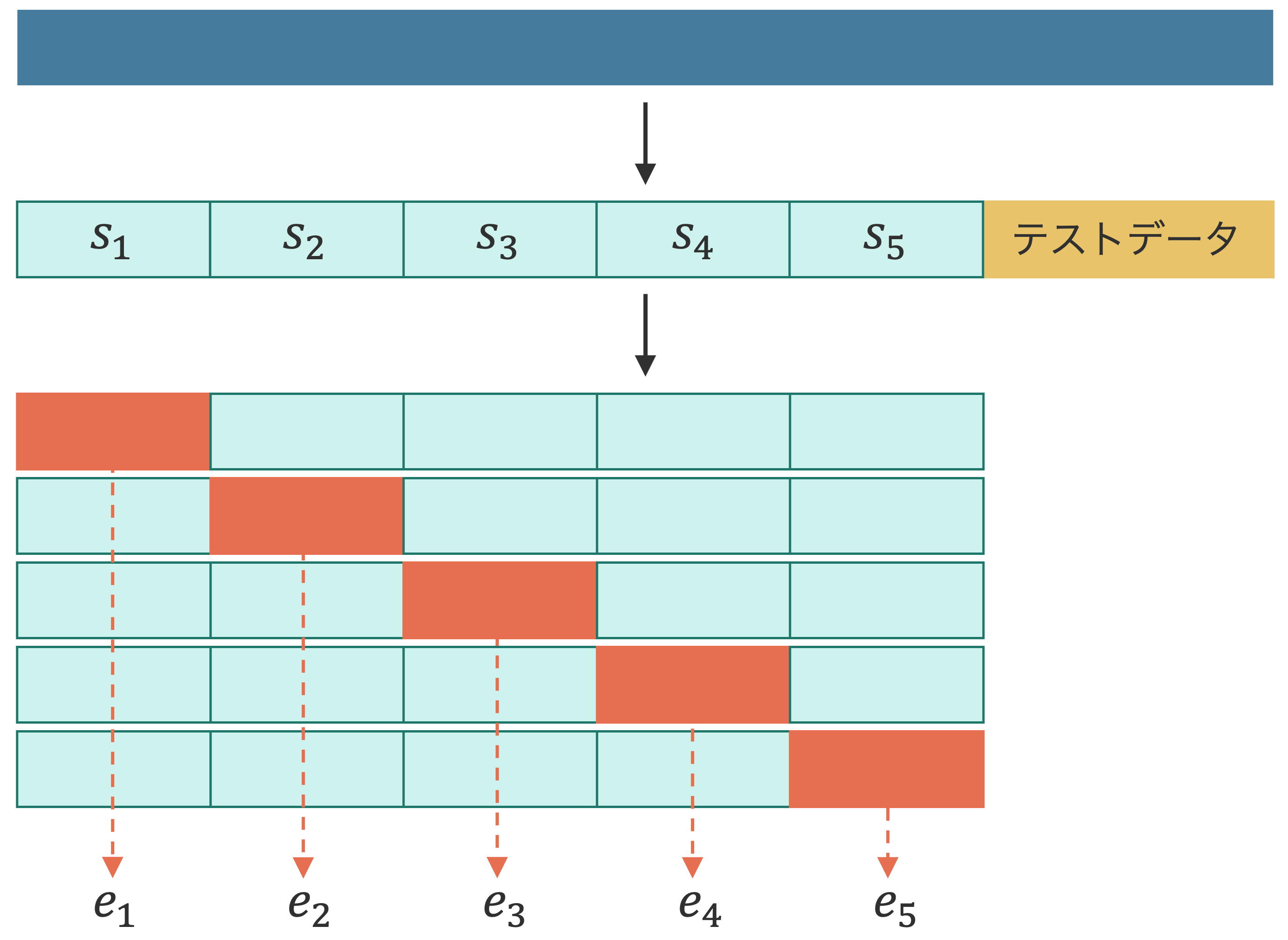
Fig. 1.2 k-分割交差検証法ではデータを訓練とテストの 2 つのサブセットに分割してから、訓練サブセットをさらに k 個のサブセットに小分けしてモデルの選択と性能評価を行います。#
例えば、k = 5 の場合、訓練データを 5 分割し、それぞれの分割データを \(s_1\)、\(s_2\)、\(s_3\)、\(s_4\)、\(s_5\) とします。次に、\(s_2\)、\(s_3\)、\(s_4\)、\(s_5\) の 4 つのサブセットを用いてモデルを訓練し、その後 \(s_1\) を検証用に用います。その評価指標(例えば F1 スコアなど)を \(e_1\) とします。続けて、同様にして \(s_1\)、\(s_3\)、\(s_4\)、\(s_5\) でモデルを訓練し、\(s_2\) で検証して、検証指標として \(e_2\) を得ます。このように、各サブセットが検証に利用されるまで、サブセットを順に入れ替えて学習と評価を行い、5 つの評価指標を計算します。最後に、これらの評価指標の平均を計算し、これをモデルの評価性能とします。ここでモデルが複数あれば、それぞれのモデルに対する平均指標が計算されるため、そのらの平均指標を参考にして最適なモデルを選択します。
最適なモデルが選択されると、k 個のサブセットを合わせて、その最適なモデルを訓練し直し、最後にテストサブセットで汎化性能を評価します。
以上で見られるように、k-分割交差検証法では最適なモデルを選択するために、k 種類の検証サブセット利用しています。この点において、一つの検証サブセットだけで最適なモデルを選択しようとするホールドアウトに比べて、十分に汎化性能の高いモデルを選択できるようになります。
1.3.3. 一個抜き交差検証#
一個抜き交差検証(leave-one-out cross validation; LOOCV)は、データセットから 1 つだけ抜き出してテストデータとし、残りのデータを訓練データとしてモデルの学習と評価を行う手法です。k-分割交差検証法において k をデータ数とした場合と同等の手法となります。
LOOCV は、データポイント数が少ない場合には有効ですが、データの数が多い場合には適していません。その理由の一つとして、LOOCV ではほぼ全てのデータを訓練に使用するため、モデルが訓練データに対して過剰に適合(過学習)する傾向があることが挙げられます。結果として、既存のデータを非常によく説明する一方で、未知のデータに対する汎化性能が低下する可能性があります。さらに、LOOCV は計算コストが高い点も問題です。データポイントの数が多い場合、学習と評価の回数がそのデータ数に比例して増加するため、計算負荷が大きくなります。これらの理由から、データ数が多い場合には、k-分割交差検証法のような他の方法が一般的に推奨されます。適切な交差検証手法を選択することは、未知データへの性能を正確に評価し、過剰適合を防ぐために重要です。LOOCV を利用する際には、データセットの規模や計算資源の制約を慎重に検討する必要があります。