4.5. 演習:小麦穂検出#
穂数や開花数、結実数などを数えることは、フェノタイピングにおいて欠かせない作業である。しかし、実験圃場全体を対象としたフェノタイピングには高いコストがかかる。そのため、現在では深層学習による画像認識を活用したフェノタイピングが一般的となっている。本節では、小麦の穂を検出し、計数を行う例を示す。
4.5.1. 演習準備#
4.5.1.1. ライブラリ#
本節で利用するライブラリを読み込みます。NumPy、Pnadas、Matplotlib、Pillow(PIL)などのライブライは、モデルの性能や推論結果などの可視化に利用します。scikit-learn(sklearn)、PyTorch(torch)、torchvision、torchmetrics は機械学習関連のライブラリであり、モデルの構築、検証や推論などに利用します。
import os
import numpy as np
import pandas as pd
import PIL.Image
import matplotlib.pyplot as plt
import torch
import torchvision
import torchmetrics
print(f'torch v{torch.__version__}; torchvision v{torchvision.__version__}')
torch v2.8.0+cu126; torchvision v0.23.0+cu126
ライブラリの読み込み時に ImportError や ModuleNotFoundError が発生した場合は、該当するライブラリをインストールしてください。ライブラリのバージョンを揃える必要はありませんが、PyTorch(torch)および torchvision が上記のバージョンと異なる時、実行中に警告メッセージが現れたり、同じ結果にならなかったりする可能性があります。
4.5.1.2. データセット#
本節では、Global WHEAT Dataset[1] を使用します。このデータセットには、さまざまな圃場で撮影された画像が含まれており、それらは 1024×1024 ピクセルの正方形に切り取られています。世界各地で栽培されている小麦の品種を幅広くカバーしており、成熟度も異なる多様な画像が含まれているため、実践的なデータセットとなっています。各画像には、小麦の穂が存在する位置のバウンディングボックスの座標情報が CSV 形式で提供されています。

Fig. 4.13 Global WHEAT Dataset に含まれる画像のサンプル。#
オリジナルのデータセットは非常に多くの画像を含んでいるため、本演習では、限られた時間内で訓練やテストを実施できるように、訓練データ 200 枚、検証データ 100 枚、テストデータ 100 枚に調整したサブセットを使用します。また、このサブセットのアノテーションデータは、PyTorch が利用しやすいように CSV から COCO フォーマットに変更してあります。このサブセットは、Jupyter Notebook 上で次のコマンドを実行することでダウンロードできます。
!wget https://dl.biopapyrus.jp/data/gwhd.zip
!unzip gwhd.zip
4.5.1.3. 画像前処理#
物体検出のタスクでは、画像とともに、検出対象の物体を囲むバウンディングボックスの座標とラベル(ここでは小麦の「穂」)をモデルに与え、学習させる必要があります。本節では、画像とバウンディングボックスの座標、およびそのラベルを適切に対応づけるための前処理コードを作成します。この前処理により、画像と COCO フォーマットのアノテーションが対応づけられ、PyTorch に入力できる形式となるため、学習をスムーズに行うことが可能になります。
なお、PyTorch では、アノテーションのない画像を処理する際にエラーが発生するため、小麦の穂が含まれていない画像に対しては特別な処理を施します。具体的には、ダミーのバウンディングボックス([0, 0, 1, 1])を設定し、そのラベルを背景クラス(0)として扱うことで、エラーを回避します。この対応により、対象物が存在しない画像も問題なく処理できるようになります。
class CocoDataset(torchvision.datasets.CocoDetection):
def __init__(self, root, annFile):
super(CocoDataset, self).__init__(root, annFile)
def __getitem__(self, idx):
img, target = super(CocoDataset, self).__getitem__(idx)
boxes = []
labels = []
for obj in target:
bbox = obj['bbox']
bbox = [bbox[0], bbox[1], bbox[0] + bbox[2], bbox[1] + bbox[3]]
boxes.append(bbox)
labels.append(obj['category_id'])
if len(boxes) == 0:
boxes = [[0, 0, 1, 1]]
labels = [0]
img = torchvision.transforms.functional.to_tensor(img)
target = {
'boxes': torch.as_tensor(boxes, dtype=torch.float32),
'labels': torch.as_tensor(labels, dtype=torch.int64),
}
return img, target
ここでは、画像分類と同様に、畳み込みニューラルネットワーク(CNN)に入力する画像のサイズを、指定されたサイズに変更する必要があります。一般的な物体検出モデルでは、長方形の画像を入力として扱うことが多いですが、今回のデータセットは正方形の画像で構成されています。そのため、独自のコードを用いて適切なサイズ調整を行うことで、より高い性能が期待できます。しかし、この作業は煩雑であるため、本節では CocoDetection クラスに実装されているデフォルトの機能を利用するにとどめます。
また、モデルを訓練する際には、画像の拡大縮小や平行移動、回転などのデータ拡張を行う必要があります。これに伴い、バウンディングボックスの座標も同様に再計算しなければなりません。しかし、これらの処理を追加するとコードが複雑になり、全体の流れがわかりにくくなるため、本節ではデータ拡張の処理は省略します。
4.5.1.4. 計算デバイス#
計算を行うデバイスを設定します。PyTorch が GPU を認識できる場合は GPU を利用し、認識できない場合は CPU を使用するように設定します。
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
4.5.2. モデル構築#
本節では、物体検出アーキテクチャとしてよく知られている Faster R-CNN を使用します。torchvision.models.detection で提供されているアーキテクチャは、車や人など 90 種類の一般的なオブジェクトを対象としています。これに対して、本節では、小麦の穂という 1 種類のオブジェクトのみを検出を目的としています。そのため、torchvision.models.detection から読み込んだアーキテクチャの出力層のユニット数を、検出対象の種類数に合わせる必要があります。
物体検出アーキテクチャでは、背景を一つのクラスとして扱うため、出力数を修正するとき、検出対象数に 1 を加えた値で修正します。例えば、穂検出の場合は、出力層の数を 2 とします。この修正は、アーキテクチャを呼び出すたびに行う必要があり、手間がかかります。そこで、一連の処理を関数として定義してから利用します。
def fasterrcnn(num_classes, weights=None):
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(weights='DEFAULT')
in_features = model.roi_heads.box_predictor.cls_score.in_features
num_classes = num_classes + 1 # class + background
model.roi_heads.box_predictor = torchvision.models.detection.faster_rcnn.FastRCNNPredictor(in_features, num_classes)
if weights is not None:
model.load_state_dict(torch.load(weights))
return model
model = fasterrcnn(num_classes=1)
model.to(device)
Show code cell output
FasterRCNN(
(transform): GeneralizedRCNNTransform(
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
Resize(min_size=(800,), max_size=1333, mode='bilinear')
)
(backbone): BackboneWithFPN(
(body): IntermediateLayerGetter(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=0.0)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): FrozenBatchNorm2d(256, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=0.0)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=0.0)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=0.0)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(512, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(1024, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=0.0)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=0.0)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(2048, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=0.0)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=0.0)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=0.0)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=0.0)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=0.0)
(relu): ReLU(inplace=True)
)
)
)
(fpn): FeaturePyramidNetwork(
(inner_blocks): ModuleList(
(0): Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
)
(1): Conv2dNormActivation(
(0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
)
(2): Conv2dNormActivation(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
)
(3): Conv2dNormActivation(
(0): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
)
)
(layer_blocks): ModuleList(
(0-3): 4 x Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(extra_blocks): LastLevelMaxPool()
)
)
(rpn): RegionProposalNetwork(
(anchor_generator): AnchorGenerator()
(head): RPNHead(
(conv): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
)
)
(cls_logits): Conv2d(256, 3, kernel_size=(1, 1), stride=(1, 1))
(bbox_pred): Conv2d(256, 12, kernel_size=(1, 1), stride=(1, 1))
)
)
(roi_heads): RoIHeads(
(box_roi_pool): MultiScaleRoIAlign(featmap_names=['0', '1', '2', '3'], output_size=(7, 7), sampling_ratio=2)
(box_head): TwoMLPHead(
(fc6): Linear(in_features=12544, out_features=1024, bias=True)
(fc7): Linear(in_features=1024, out_features=1024, bias=True)
)
(box_predictor): FastRCNNPredictor(
(cls_score): Linear(in_features=1024, out_features=2, bias=True)
(bbox_pred): Linear(in_features=1024, out_features=8, bias=True)
)
)
)
4.5.3. モデル訓練#
モデルが学習データを効率よく学習できるようにするため、学習アルゴリズム(optimizer)、学習率(lr)、および学習率を調整するスケジューラ(lr_scheduler)を設定します。なお、画像分類では損失関数も合わせて定義していますが、物体検出では分類誤差を計算する損失関数とバウンディングボックスの座標の誤差を計算する損失関数の二種類を定義する必要があります。これらの関数はすでにモデルの中で定義されているため、ここであらためて定義する必要はありません。
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-5, weight_decay=1e-5)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.01)
次に、訓練データと検証データを読み込み、モデルが入力できる形式に整えます。
train_loader = torch.utils.data.DataLoader(
CocoDataset('gwhd', 'gwhd/train.json'),
batch_size=4, shuffle=True, collate_fn=lambda x: tuple(zip(*x)))
valid_loader = torch.utils.data.DataLoader(
CocoDataset('gwhd', 'gwhd/valid.json'),
batch_size=4, shuffle=False, collate_fn=lambda x: tuple(zip(*x)))
Show code cell output
loading annotations into memory...
Done (t=0.21s)
creating index...
index created!
loading annotations into memory...
Done (t=0.01s)
creating index...
index created!
準備が整ったら、訓練を開始します。訓練プロセスでは、訓練と検証を交互に繰り返します。訓練では、訓練データを使ってモデルのパラメータを更新し、その際の損失(誤差)を記録します。検証では、検証データを使ってモデルの予測性能(mAP)を計算し、その結果を記録します。
num_epochs = 10
metric_dict = []
for epoch in range(num_epochs):
# training phase
model.train()
epoch_loss_dict = {}
for images, targets in train_loader:
images = [img.to(device) for img in images]
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
batch_loss_dict = model(images, targets)
batch_tol_loss = 0
for loss_type, loss_val in batch_loss_dict.items():
batch_tol_loss += loss_val
if loss_type in epoch_loss_dict:
epoch_loss_dict[f'train_{loss_type}'] += loss_val.item()
else:
epoch_loss_dict[f'train_{loss_type}'] = loss_val.item()
# update weights
optimizer.zero_grad()
batch_tol_loss.backward()
optimizer.step()
lr_scheduler.step()
# validation phase
model.eval()
metric = torchmetrics.detection.mean_ap.MeanAveragePrecision()
with torch.no_grad():
for images, targets in valid_loader:
images = [img.to(device) for img in images]
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
metric.update(model(images), targets)
# record training loss
epoch_loss_dict['train_loss_total'] = sum(epoch_loss_dict.values())
metric_dict.append({k: v / len(train_loader) for k, v in epoch_loss_dict.items()})
for k, v in metric.compute().items():
if k != 'classes':
metric_dict[-1][k] = v.item()
metric_dict[-1]['epoch'] = epoch + 1
print(metric_dict[-1])
Show code cell output
{'train_loss_classifier': 0.00780474603176117, 'train_loss_box_reg': 0.014749168157577515, 'train_loss_objectness': 0.0043215429782867435, 'train_loss_rpn_box_reg': 0.002928348183631897, 'train_loss_total': 0.029803805351257324, 'map': 0.11185730993747711, 'map_50': 0.29947367310523987, 'map_75': 0.053071845322847366, 'map_small': 0.0, 'map_medium': 0.22846820950508118, 'map_large': 0.21736669540405273, 'mar_1': 0.004814497195184231, 'mar_10': 0.04219386726617813, 'mar_100': 0.1723354011774063, 'mar_small': 0.0, 'mar_medium': 0.3481065630912781, 'mar_large': 0.35424163937568665, 'map_per_class': -1.0, 'mar_100_per_class': -1.0, 'epoch': 1}
{'train_loss_classifier': 0.005478405952453613, 'train_loss_box_reg': 0.01175462007522583, 'train_loss_objectness': 0.00239228755235672, 'train_loss_rpn_box_reg': 0.0017592206597328186, 'train_loss_total': 0.021384534239768983, 'map': 0.1594734787940979, 'map_50': 0.3782441318035126, 'map_75': 0.0993095189332962, 'map_small': 0.00243944744579494, 'map_medium': 0.31865420937538147, 'map_large': 0.3446124494075775, 'mar_1': 0.006101222243160009, 'mar_10': 0.053978126496076584, 'mar_100': 0.20809563994407654, 'mar_small': 0.014285714365541935, 'mar_medium': 0.41170018911361694, 'mar_large': 0.46825191378593445, 'map_per_class': -1.0, 'mar_100_per_class': -1.0, 'epoch': 2}
{'train_loss_classifier': 0.0057848507165908815, 'train_loss_box_reg': 0.011752266883850098, 'train_loss_objectness': 0.0015963129699230194, 'train_loss_rpn_box_reg': 0.0013866990804672242, 'train_loss_total': 0.020520129650831224, 'map': 0.17338129878044128, 'map_50': 0.3964572846889496, 'map_75': 0.11967474222183228, 'map_small': 0.005467588547617197, 'map_medium': 0.3466123938560486, 'map_large': 0.3789896070957184, 'mar_1': 0.0062298947013914585, 'mar_10': 0.05710915848612785, 'mar_100': 0.2197941243648529, 'mar_small': 0.02410714328289032, 'mar_medium': 0.4360668659210205, 'mar_large': 0.48688945174217224, 'map_per_class': -1.0, 'mar_100_per_class': -1.0, 'epoch': 3}
{'train_loss_classifier': 0.004168342351913452, 'train_loss_box_reg': 0.00929815948009491, 'train_loss_objectness': 0.0010756903886795044, 'train_loss_rpn_box_reg': 0.0008602633327245712, 'train_loss_total': 0.015402455553412438, 'map': 0.18758176267147064, 'map_50': 0.4128899574279785, 'map_75': 0.14340558648109436, 'map_small': 0.011377314105629921, 'map_medium': 0.37433281540870667, 'map_large': 0.40356209874153137, 'mar_1': 0.006583744194358587, 'mar_10': 0.058889128267765045, 'mar_100': 0.2314818799495697, 'mar_small': 0.04107142984867096, 'mar_medium': 0.46346303820610046, 'mar_large': 0.4895886778831482, 'map_per_class': -1.0, 'mar_100_per_class': -1.0, 'epoch': 4}
{'train_loss_classifier': 0.0046394428610801695, 'train_loss_box_reg': 0.009396416544914245, 'train_loss_objectness': 0.0006554140150547027, 'train_loss_rpn_box_reg': 0.0010194753110408783, 'train_loss_total': 0.015710748732089996, 'map': 0.1938146948814392, 'map_50': 0.41892632842063904, 'map_75': 0.152143657207489, 'map_small': 0.016125181689858437, 'map_medium': 0.38666364550590515, 'map_large': 0.420168936252594, 'mar_1': 0.006637358106672764, 'mar_10': 0.06022946536540985, 'mar_100': 0.23677890002727509, 'mar_small': 0.04107142984867096, 'mar_medium': 0.47273439168930054, 'mar_large': 0.5074549913406372, 'map_per_class': -1.0, 'mar_100_per_class': -1.0, 'epoch': 5}
{'train_loss_classifier': 0.005164858102798462, 'train_loss_box_reg': 0.010507566928863525, 'train_loss_objectness': 0.0011481288820505142, 'train_loss_rpn_box_reg': 0.0015251682698726654, 'train_loss_total': 0.018345722183585166, 'map': 0.1938963085412979, 'map_50': 0.41922980546951294, 'map_75': 0.15144191682338715, 'map_small': 0.015703700482845306, 'map_medium': 0.3859480321407318, 'map_large': 0.4219834506511688, 'mar_1': 0.006637358106672764, 'mar_10': 0.060508254915475845, 'mar_100': 0.2366180568933487, 'mar_small': 0.04107142984867096, 'mar_medium': 0.4720292389392853, 'mar_large': 0.5089974403381348, 'map_per_class': -1.0, 'mar_100_per_class': -1.0, 'epoch': 6}
{'train_loss_classifier': 0.004948394894599914, 'train_loss_box_reg': 0.00936256766319275, 'train_loss_objectness': 0.0011392372846603393, 'train_loss_rpn_box_reg': 0.0012621371448040008, 'train_loss_total': 0.016712336987257003, 'map': 0.19390438497066498, 'map_50': 0.41953790187835693, 'map_75': 0.15154960751533508, 'map_small': 0.016758106648921967, 'map_medium': 0.3863990306854248, 'map_large': 0.42089900374412537, 'mar_1': 0.006551576312631369, 'mar_10': 0.06047608703374863, 'mar_100': 0.23660732805728912, 'mar_small': 0.04196428507566452, 'mar_medium': 0.4717941880226135, 'mar_large': 0.5098971724510193, 'map_per_class': -1.0, 'mar_100_per_class': -1.0, 'epoch': 7}
{'train_loss_classifier': 0.0044310265779495235, 'train_loss_box_reg': 0.009242750406265259, 'train_loss_objectness': 0.0007405233383178711, 'train_loss_rpn_box_reg': 0.0017590676248073578, 'train_loss_total': 0.016173367947340013, 'map': 0.19397029280662537, 'map_50': 0.41947412490844727, 'map_75': 0.15329256653785706, 'map_small': 0.016446931287646294, 'map_medium': 0.3871362507343292, 'map_large': 0.42153504490852356, 'mar_1': 0.006540853530168533, 'mar_10': 0.060626205056905746, 'mar_100': 0.2366502285003662, 'mar_small': 0.04196428507566452, 'mar_medium': 0.4717680811882019, 'mar_large': 0.5105398297309875, 'map_per_class': -1.0, 'mar_100_per_class': -1.0, 'epoch': 8}
{'train_loss_classifier': 0.005365993380546569, 'train_loss_box_reg': 0.010467644929885864, 'train_loss_objectness': 0.0009823833405971528, 'train_loss_rpn_box_reg': 0.001370960772037506, 'train_loss_total': 0.018186982423067093, 'map': 0.193924218416214, 'map_50': 0.41910478472709656, 'map_75': 0.15325775742530823, 'map_small': 0.01583831198513508, 'map_medium': 0.3859499990940094, 'map_large': 0.4216136336326599, 'mar_1': 0.0064657945185899734, 'mar_10': 0.06046536564826965, 'mar_100': 0.23672528564929962, 'mar_small': 0.04732142761349678, 'mar_medium': 0.4718725383281708, 'mar_large': 0.5101542472839355, 'map_per_class': -1.0, 'mar_100_per_class': -1.0, 'epoch': 9}
{'train_loss_classifier': 0.00360711932182312, 'train_loss_box_reg': 0.008192124366760254, 'train_loss_objectness': 0.0007042668759822846, 'train_loss_rpn_box_reg': 0.0011732007563114166, 'train_loss_total': 0.013676711320877076, 'map': 0.19391635060310364, 'map_50': 0.419181764125824, 'map_75': 0.15340189635753632, 'map_small': 0.014966358430683613, 'map_medium': 0.3858858048915863, 'map_large': 0.42138782143592834, 'mar_1': 0.006497962865978479, 'mar_10': 0.060433197766542435, 'mar_100': 0.23671455681324005, 'mar_small': 0.04196428507566452, 'mar_medium': 0.471950888633728, 'mar_large': 0.5104113221168518, 'map_per_class': -1.0, 'mar_100_per_class': -1.0, 'epoch': 10}
訓練データに対する損失と検証データに対する予測性能(mAP)を可視化し、訓練過程を評価します。
Show code cell source
metric_dict = pd.DataFrame(metric_dict)
fig, ax = plt.subplots(1, 2)
ax[0].plot(metric_dict['epoch'], metric_dict['train_loss_total'], label='total')
ax[0].plot(metric_dict['epoch'], metric_dict['train_loss_classifier'], label='classification')
ax[0].plot(metric_dict['epoch'], metric_dict['train_loss_box_reg'], label='bbox')
ax[0].set_xlabel('epoch')
ax[0].set_ylabel('loss')
ax[0].set_title('Train')
ax[0].legend()
ax[1].plot(metric_dict['epoch'], metric_dict['map_50'])
ax[1].set_ylim(0, 1)
ax[1].set_xlabel('epoch')
ax[1].set_ylabel('mAP (50%)')
ax[1].set_title('Validation')
plt.tight_layout()
fig.show()
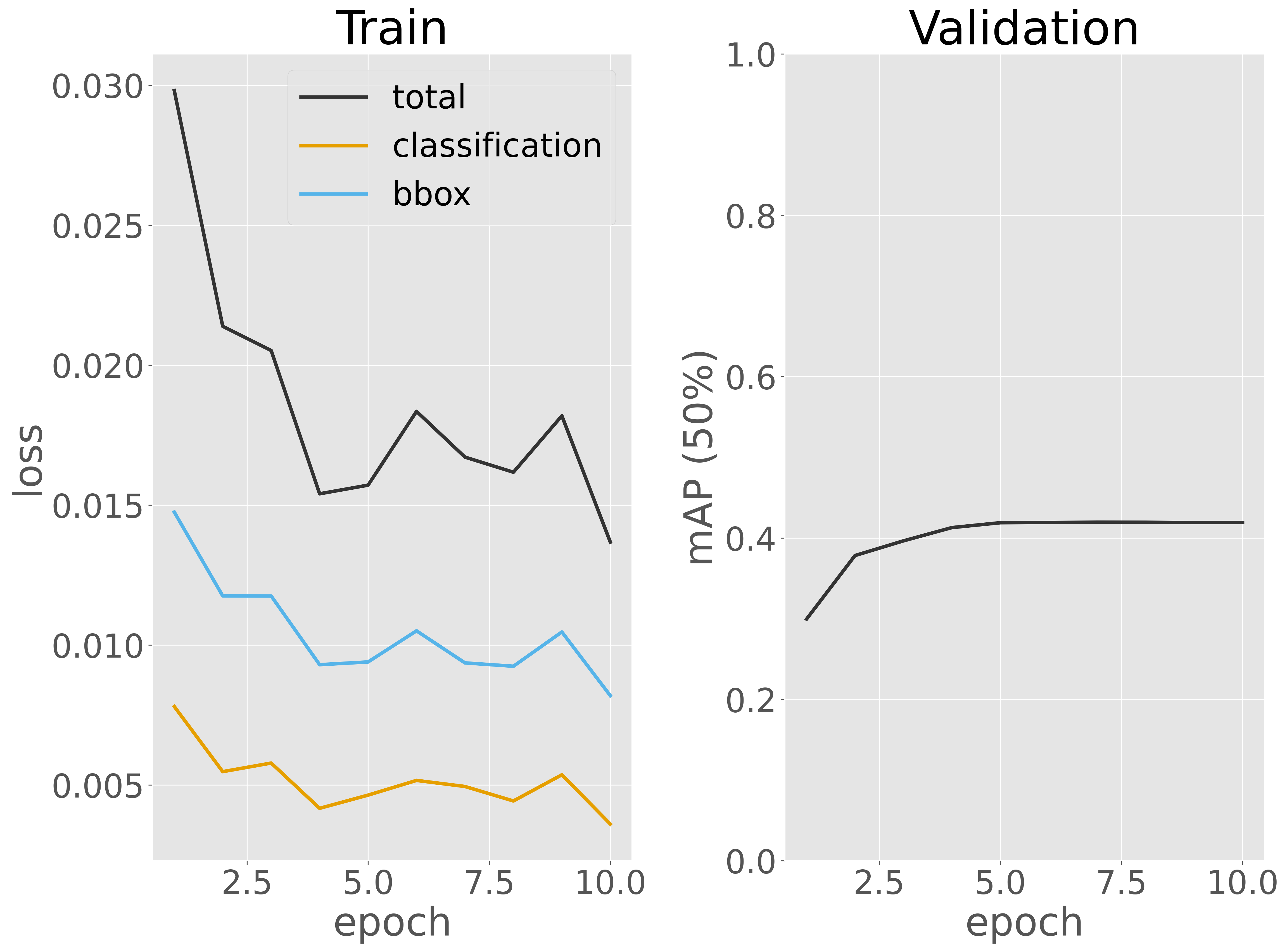
可視化の結果から、エポック数が増えるにつれて訓練データに対する損失が継続的に減少していることが確認できます。10 エポック目においても訓練損失が減少し続ける傾向がまだ見られます。一方、検証データに対する検出性能(mAP 50%)は、5 エポックを過ぎたあたりでほぼ収束しているようです。ただし、値が と低く、十分とはいえません。このため、訓練エポック数をさらに増やして損失や検証性能の推移を詳しく観察するか、必要に応じてデータを増やして再訓練することが考えられます。ただし、本節では、時間の制約があるため、訓練はここで終了します。
次に、この手順を SSD や YOLO など、他の深層ニューラルネットワークのアーキテクチャに適用し、それぞれの検証性能を比較します。この比較により、データセットに最も適したアーキテクチャを選定します。ただし、本節では時間の関係で他のアーキテクチャを構築せず、上で構築した Faster R-CNN を最適なアーキテクチャとして扱い、次のステップに進みます。
次のステップでは、訓練サブセットと検証サブセットを統合し、最適と判断したアーキテクチャを最初から訓練します。
モデル選択のために行われた訓練と検証の結果から、数エポックの訓練だけでも十分に高い予測性能を獲得できたことがわかったので、ここでは訓練サブセットと検証サブセットを統合したデータに対して 5 エポックだけ訓練させます。
# model
model = fasterrcnn(num_classes=1)
model.to(device)
# training parameters
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4, weight_decay=1e-4)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)
# training data
train_loader = torch.utils.data.DataLoader(
CocoDataset('gwhd', 'gwhd/trainvalid.json'),
batch_size=4, shuffle=True, collate_fn=lambda x: tuple(zip(*x)))
# training
num_epochs = 5
metric_dict = []
for epoch in range(num_epochs):
model.train()
epoch_loss_dict = {}
for images, targets in train_loader:
images = [img.to(device) for img in images]
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
batch_loss_dict = model(images, targets)
batch_tol_loss = 0
for loss_type, loss_val in batch_loss_dict.items():
batch_tol_loss += loss_val
if loss_type in epoch_loss_dict:
epoch_loss_dict[f'train_{loss_type}'] += loss_val.item()
else:
epoch_loss_dict[f'train_{loss_type}'] = loss_val.item()
optimizer.zero_grad()
batch_tol_loss.backward()
optimizer.step()
lr_scheduler.step()
# record training loss
epoch_loss_dict['train_loss_total'] = sum(epoch_loss_dict.values())
metric_dict.append({k: v / len(train_loader) for k, v in epoch_loss_dict.items()})
metric_dict[-1]['epoch'] = epoch + 1
print(metric_dict[-1])
Show code cell output
loading annotations into memory...
Done (t=0.03s)
creating index...
index created!
{'train_loss_classifier': 0.003711247444152832, 'train_loss_box_reg': 0.007213226954142253, 'train_loss_objectness': 0.001189622978369395, 'train_loss_rpn_box_reg': 0.0017838287353515625, 'train_loss_total': 0.013897926112016042, 'epoch': 1}
{'train_loss_classifier': 0.003432156244913737, 'train_loss_box_reg': 0.006470891634623209, 'train_loss_objectness': 0.0005888478457927704, 'train_loss_rpn_box_reg': 0.0011029879252115885, 'train_loss_total': 0.011594883650541305, 'epoch': 2}
{'train_loss_classifier': 0.003315626382827759, 'train_loss_box_reg': 0.006585582892100017, 'train_loss_objectness': 0.0006011553605397542, 'train_loss_rpn_box_reg': 0.0010920095443725587, 'train_loss_total': 0.011594374179840088, 'epoch': 3}
{'train_loss_classifier': 0.002370009223620097, 'train_loss_box_reg': 0.00492500106493632, 'train_loss_objectness': 0.00035360589623451233, 'train_loss_rpn_box_reg': 0.0003327547013759613, 'train_loss_total': 0.00798137088616689, 'epoch': 4}
{'train_loss_classifier': 0.0021667055288950602, 'train_loss_box_reg': 0.004448275566101074, 'train_loss_objectness': 0.00032506259779135384, 'train_loss_rpn_box_reg': 0.0006728488703568777, 'train_loss_total': 0.007612892563144366, 'epoch': 5}
訓練が完了したら、訓練済みモデルの重みをファイルに保存します。
model.to('cpu')
torch.save(model.state_dict(), 'gwhd.pth')
4.5.4. モデル評価#
最適なモデルが得られたら、次にテストデータを用いて詳細な評価を行います。ここでは、物体検出で一般的に用いられる評価指標である mAP を計算し、さらに各画像に対して予測された穂の数と実際の穂の数も記録します。なお、予測スコアが 0.5 を超える領域を予測領域として、閾値を設定しています。
test_loader = torch.utils.data.DataLoader(
CocoDataset('gwhd', 'gwhd/test.json'),
batch_size=4, shuffle=True, collate_fn=lambda x: tuple(zip(*x)))
model = fasterrcnn(num_classes=1, weights='gwhd.pth')
model.to(device)
model.eval()
n_gt = []
n_predicted = []
metric = torchmetrics.detection.mean_ap.MeanAveragePrecision()
with torch.no_grad():
for images, targets in test_loader:
images = [img.to(device) for img in images]
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
outputs = model(images)
for target, output in zip(targets, outputs):
n_gt.append(len(target['labels']))
_n = 0
for score in output['scores']:
if score > 0.5:
_n += 1
n_predicted.append(_n)
metric.update(outputs, targets)
metrics = {}
for k, v in metric.compute().items():
metrics[k] = v.cpu().detach().numpy().tolist()
Show code cell output
loading annotations into memory...
Done (t=0.01s)
creating index...
index created!
metrics
{'map': 0.228929340839386,
'map_50': 0.44381335377693176,
'map_75': 0.20963236689567566,
'map_small': 0.07064513862133026,
'map_medium': 0.4600837230682373,
'map_large': 0.46558666229248047,
'mar_1': 0.008250707760453224,
'mar_10': 0.07203730195760727,
'mar_100': 0.26406988501548767,
'mar_small': 0.0892857164144516,
'mar_medium': 0.5305247902870178,
'mar_large': 0.5311053991317749,
'map_per_class': -1.0,
'mar_100_per_class': -1.0,
'classes': [0, 1]}
ここで出力される指標について、map から始まる指標は mAP を表し、mar から始まる指標は mean average recall(平均再現率)を示します。mar はすべてのクラスに対する再現率を計算し、それらの平均を求めたものです。mAR 1 は、各画像に対してモデルが検出した物体のうち、最も信頼度の高い物体だけを利用して計算した再現率を表します。同様に、mAR 10 および mAR 100 は、モデルが検出した物体のうち、信頼度の高い 10 および 100 物体を利用して計算した再現率を表しています。
次に、予測した穂の数と実際の穂の数を散布図で可視化して評価します。
fig, ax = plt.subplots()
ax.scatter(n_gt, n_predicted, alpha=0.5)
mn = min(min(n_gt), min(n_predicted))
mx = max(max(n_gt), max(n_predicted))
ax.plot([mn, mx], [mn, mx], '--', label='y = x')
ax.set_xlabel('number of spikes (groundtruth)')
ax.set_ylabel('number of predicted spikes')
ax.set_aspect('equal')
ax.legend()
fig.show()
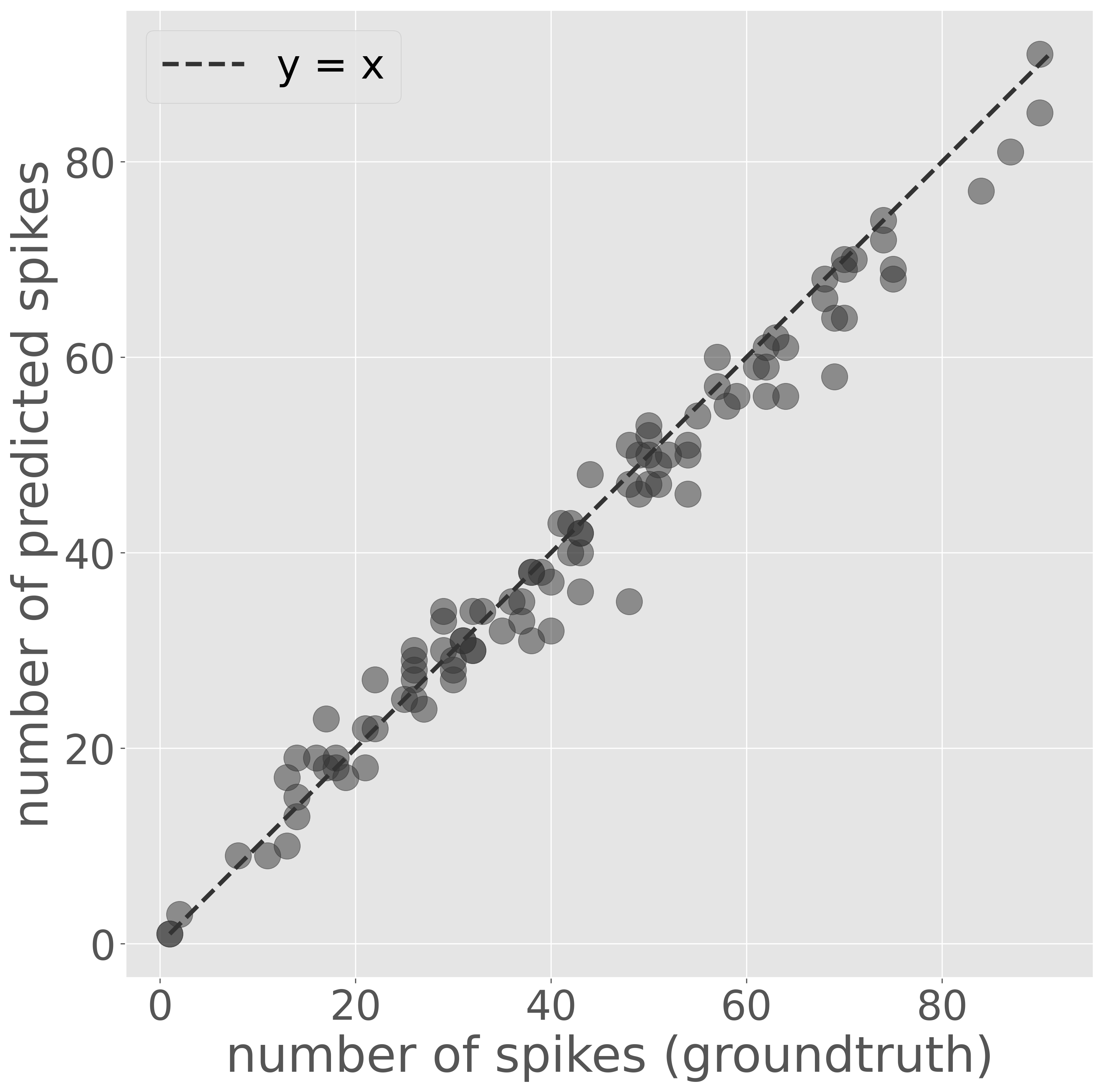
可視化の結果、予測数と実際の数が完全に一致する画像はほとんどありませんでしたが、ほとんどの画像においてほぼ正確に穂を検出できたことが確認できました。
4.5.5. 推論#
推論時にも、訓練時と同じように torchvision モジュールからアーキテクチャを呼び出し、出力層のクラス数を設定します。その後、load_state_dict メソッドを使って、訓練済みの重みファイルをモデルにロードします。これらの操作はすべて fasterrcnn 関数で定義されているので、その関数を利用します。
model = fasterrcnn(num_classes=1, weights='gwhd.pth')
model.to(device)
model.eval()
Show code cell output
FasterRCNN(
(transform): GeneralizedRCNNTransform(
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
Resize(min_size=(800,), max_size=1333, mode='bilinear')
)
(backbone): BackboneWithFPN(
(body): IntermediateLayerGetter(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=0.0)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): FrozenBatchNorm2d(256, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=0.0)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=0.0)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=0.0)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(512, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(1024, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=0.0)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=0.0)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(2048, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=0.0)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=0.0)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=0.0)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=0.0)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=0.0)
(relu): ReLU(inplace=True)
)
)
)
(fpn): FeaturePyramidNetwork(
(inner_blocks): ModuleList(
(0): Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
)
(1): Conv2dNormActivation(
(0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
)
(2): Conv2dNormActivation(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
)
(3): Conv2dNormActivation(
(0): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
)
)
(layer_blocks): ModuleList(
(0-3): 4 x Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(extra_blocks): LastLevelMaxPool()
)
)
(rpn): RegionProposalNetwork(
(anchor_generator): AnchorGenerator()
(head): RPNHead(
(conv): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
)
)
(cls_logits): Conv2d(256, 3, kernel_size=(1, 1), stride=(1, 1))
(bbox_pred): Conv2d(256, 12, kernel_size=(1, 1), stride=(1, 1))
)
)
(roi_heads): RoIHeads(
(box_roi_pool): MultiScaleRoIAlign(featmap_names=['0', '1', '2', '3'], output_size=(7, 7), sampling_ratio=2)
(box_head): TwoMLPHead(
(fc6): Linear(in_features=12544, out_features=1024, bias=True)
(fc7): Linear(in_features=1024, out_features=1024, bias=True)
)
(box_predictor): FastRCNNPredictor(
(cls_score): Linear(in_features=1024, out_features=2, bias=True)
(bbox_pred): Linear(in_features=1024, out_features=8, bias=True)
)
)
)
このモデルを利用して推論を行います。まず、1 枚の画像を指定し、PIL モジュールを用いて画像を開き、テンソル形式に変換した後、モデルに入力します。モデルは予測結果としてバウンディングボックスの座標(bboxes)、分類ラベル(labels)、および信頼スコア(scores)を出力します。ただし、信頼スコアが 0.5 未満のバウンディングボックスは採用せず、信頼スコアが高い結果のみを選択して利用します。
threshold = 0.5
image_path = 'gwhd/images/fda86ae9a.jpg'
image = PIL.Image.open(image_path).convert('RGB')
input_tensor = torchvision.transforms.functional.to_tensor(image).unsqueeze(0).to(device)
with torch.no_grad():
predictions = model(input_tensor)[0]
bboxes = predictions['boxes'][predictions['scores'] > threshold]
labels = predictions['labels'][predictions['scores'] > threshold]
scores = predictions['scores'][predictions['scores'] > threshold]
検出されたオブジェクトのバウンディングボックスを入力画像に描画します。その後、PIL および matplotlib ライブラリを使用して、画像とその検出結果を可視化します。
draw = PIL.ImageDraw.Draw(image)
for bbox, label, score in zip(bboxes, labels, scores):
x1, y1, x2, y2 = bbox
draw.rectangle(((x1, y1), (x2, y2)), outline="blue", width=3)
draw.text((x1, y1 - 10), f"{label.item()} ({score:.2f})", fill="blue")
fig = plt.figure()
ax = fig.add_subplot()
ax.imshow(image)
ax.axis('off')
fig.show()

次にこのモデルにもう一枚の画像を入力し、その推論結果を見てみましょう。
threshold = 0.5
image_path = 'gwhd/images/cb34f7509.jpg'
image = PIL.Image.open(image_path).convert('RGB')
input_tensor = torchvision.transforms.functional.to_tensor(image).unsqueeze(0).to(device)
with torch.no_grad():
predictions = model(input_tensor)[0]
bboxes = predictions['boxes'][predictions['scores'] > threshold]
labels = predictions['labels'][predictions['scores'] > threshold]
scores = predictions['scores'][predictions['scores'] > threshold]
draw = PIL.ImageDraw.Draw(image)
for bbox, label, score in zip(bboxes, labels, scores):
x1, y1, x2, y2 = bbox
draw.rectangle(((x1, y1), (x2, y2)), outline="blue", width=3)
draw.text((x1, y1 - 10), f"{label.item()} ({score:.2f})", fill="blue")
fig = plt.figure()
ax = fig.add_subplot()
ax.imshow(image)
ax.axis('off')
fig.show()

threshold = 0.5
image_path = 'gwhd/images/d3b3b5628.jpg'
image = PIL.Image.open(image_path).convert('RGB')
input_tensor = torchvision.transforms.functional.to_tensor(image).unsqueeze(0).to(device)
with torch.no_grad():
predictions = model(input_tensor)[0]
bboxes = predictions['boxes'][predictions['scores'] > threshold]
labels = predictions['labels'][predictions['scores'] > threshold]
scores = predictions['scores'][predictions['scores'] > threshold]
draw = PIL.ImageDraw.Draw(image)
for bbox, label, score in zip(bboxes, labels, scores):
x1, y1, x2, y2 = bbox
draw.rectangle(((x1, y1), (x2, y2)), outline="blue", width=3)
draw.text((x1, y1 - 10), f"{label.item()} ({score:.2f})", fill="blue")
fig = plt.figure()
ax = fig.add_subplot()
ax.imshow(image)
ax.axis('off')
fig.show()
